|
| |
| |
| |
Open en meerkeuze-vragen tekstbegrip: een onderzoek naar vraagonzuiverheid van tekstbegripvragen
H. van den Bergh
Samenvatting
Vrouwelijke leerlingen behalen vaak hogere scores dan mannelijke leerlingen op toetsen met open vragen. Worden echter de vaardigheden van de leerlingen met behulp van meerkeuze-vragen geëvalueerd, dan is genoemd verschil vaak verdwenen. Sommigen baseren hierop de conclusie dat meerkeuze-vragen vrouwelijke leerlingen benadelen. Getracht is deze conclusie aan de empirie te toetsen. In dit onderzoek bleek deze conclusie niet houdbaar, eerder het omgekeerde lijkt het geval: open vragen tekstbegrip lijken mannelijke leerlingen te benadelen: mannelijke leerlingen behalen lagere scores op tekstbegriptoetsen met open vragen dan vrouwelijke leerlingen met een vergelijkbare leesvaardigheid.
| |
1 Inleiding
Onlangs is het Centraal Schriftelijk Eindexamen tekstbegrip Nederlands voor LBO-en dat voor MAVO-kandidaten gewijzigd. Met ingang van het eindexamen van 1987 krijgen LBO- en MAVO-kandidaten hetzelfde eindexamen voor het onderdeel tekstbegrip voorgelegd. Tevens is een inhoudelijke verandering in de examens qua gehanteerde vraagvorm doorgevoerd: de zogenaamde 70/30 maatregel. Deze maatregel houdt in dat het cijfer van een kandidaat voor 70% bepaald wordt door zijn antwoorden op de gestelde meerkeuze-vragen en voor 30% door zijn antwoorden op de open vragen. (Voorheen bestond het MAVO-examen voornamelijk uit open vragen en het LBO-examen voor de helft uit open en de helft uit meerkeuze-vragen).
In examensituaties tracht men vanzelfsprekend de vaardigheden van de leerlingen zo zuiver mogelijk te evalueren. Dat wil zeggen: de meting van de vaardigheden moet zoveel mogelijk vrij zijn van voor dit doel irrelevante kenmerken of vaardigheden van de kandidaten. Een meting van het tekstbegrip van eindexamenkandidaten moet dus zo min mogelijk beïnvloed worden door: de formuleervaardigheid van de kandidaten, hun sekse, hun etnische achtergrond etc. Wanneer de niet bedoelde maar mee gemeten vaardigheden inherent zijn aan een kenmerk van de kandidaat, dan wordt de ene groep kandidaten systematisch bevoordeeld boven de andere groep kandidaten. Nemen we bij voorbeeld aan dat vrouwelijke kandidaten een beter handschrift hebben dan mannelijke kandidaten, en dat de kwaliteit van het handschrift (onbedoeld) een rol speelt bij de beoordeling van de antwoorden op open tekstbegripvragen, dan zouden vrouwelijke kandidaten systematisch bevoordeeld worden. We noemen de meting van het tekstbegrip dan biased tegen mannelijke kandidaten.
Om bias, of onzuiverheid, van een meting zoveel mogelijk te voorkomen, wordt regelmatig aanbevolen om de vaardigheid in kwestie op verschillende manieren te meten; bij voorbeeld met open én meerkeuze-vragen (zie o.a. Campbell & Fiske, 1959; Cook & Campbell, 1979; Fiske, 1987).
| |
| |
Een aantal onderzoekers heeft gedemonstreerd dat het voor een leerling verschil maakt of zijn/haar vaardigheden geëvalueerd worden met objectieve toetsen dan wel met toetsen waarbij open vragen gesteld worden. Het bleek dat de mannelijke kandidaten relatief hogere scores behaalden wanneer de vaardigheden met behulp van meerkeuze-vragen gemeten werden, terwijl vrouwelijke kandidaten relatief in het voordeel waren wanneer de vaardigheden in kwestie met open vragen geëvalueerd werden. In de meeste studies werden de prestaties van de leerlingen op objectieve toetsen gerelateerd aan hun schoolen examenprestaties; er werd een vergelijking gemaakt tussen de rangorde van de schoolof examenprestaties van de leerlingen enerzijds en hun prestaties op objectieve toetsen anderzijds (zie o.a. Forrest 1971; Forrest & Smith, 1972; Linn, 1973; Nutall e.a., 1974; Willmott, 1977; Bolger, 1984).
Murphy (1982) hanteerde een iets andere onderzoeksmethode, waarbij hij overigens tot dezelfde conclusie komt. Murphy (1982) bestudeerde de prestaties van Engelse leerlingen op eindexamens voor en na invoering van objectieve toetsen in het Engelse schoolsysteem. Hij constateerde dat mannelijke kandidaten op de nieuwe objectieve toetsen beduidend hoger presteerden dan vrouwelijke kandidaten. Dat wil zeggen: het percentage mannelijke kandidaten dat slaagde voor het examen na invoering van de objectieve toetsen lag zo'n 10% hoger dan het equivalente percentage vrouwelijke kandidaten. Voorts concludeerde Murphy (o.c.) dat het verschil in gemiddelde prestatie van mannelijke en vrouwelijke kandidaten kleiner was bij objectieve toetsen dan bij toetsen met open vragen. Dit was aanleiding om te stellen dat examens met meerkeuze-vragen ‘eerlijker’ zijn dan examens met open vragen, hoewel de invoering van toetsen met meerkeuze-vragen vrouwelijke kandidaten benadeelt.
Voor dit verschijnsel, de relatief hogere prestaties van mannelijke kandidaten op objectieve toetsen, worden diverse verklaringen gesuggereerd. Er is geopperd dat vrouwelijke kandidaten een te hoge score behalen in relatie tot hun vaardigheid op toetsen met open vragen, doordat zij zorgvuldiger en consciëntieuzer zijn (Stanley, 1967), of doordat zij formuleervaardiger zijn (Murphy, 1982), of doordat hun handschrift ‘netter’ is waardoor hun open-vraag-produkten beter gekwalificeerd worden (Bolger, 1984). Overigens meent Jensen (1980), dat de verschillen in prestaties ten gevolge van de toetsingprocedure overdreven worden, zeker die in Amerikaans onderzoek, hoewel hij dit standpunt in een later publikatie nuanceert (Modgil & Modgil, 1987).
In de genoemde studies worden de gemiddelde toetsprestaties van soms grote groepen leerlingen (tot wel enkele duizenden) vergeleken. Dit heeft als nadeel dat ervan uit gegaan wordt dat beide groepen leerlingen (gemiddeld) even goed presteren en dat de verdeling van de toetsscores identiek is in beide groepen. Dit is voor taalvaardigheid en aspecten van taalvaardigheid een aanvechtbare assumptie, daar er in het algemeen vanuit wordt gegaan dat vrouwelijke leerlingen taalvaardiger zijn dan mannelijke leerlingen. Het lijkt derhalve wenselijk om de prestaties van de leerlingen op item-niveau te bestuderen. Immers, dan kunnen de prestaties van de leerlingen op de diverse items conditioneel op de vaardigheid vergeleken worden. Dat wil zeggen: er kan per vaardigheidsniveau (bij voorbeeld: goede, middelmatige en slechte presteerders) een analyse gemaakt van de prestaties op een item. Als een item dan onzuiver is op het kenmerk waarop de leerlingen geclassificeerd zijn, dan zullen meer leerlingen van de ene groep het item correct beantwoord hebben dan leerlingen van de andere groep.
In dit onderzoek worden de prestaties van leerlingen uit de derde klas LBO en MAVO op tekstbegriptoetsen op item-niveau bestudeerd. Nagegaan wordt of meerkeuze-tekstbe- | |
| |
gripvragen vaker onzuiver zijn tegen sekse dan open tekstbegripvragen en de consequenties van vraagonzuiverheid worden gekoppeld aan de toetspraktijk in het Centraal Schriftelijk Examen Nederlands.
| |
2 Methode en procedures
Er zijn vier tekstbegriptoetsen geconstrueerd, die twee aan twee vergelijkbaar zijn. Dat wil zeggen: bij twee teksten werden 50 (tweemaal 25) open vragen gesteld, en bij de andere twee toetsen werden dezelfde vragen gesteld, maar nu in vierkeuze-vorm. Omdat dit onderzoek plaats vond in het kader van een evaluatie van de nieuwe examens Nederlands voor LBO- en MAVO-kandidaten, zijn de twee teksten ontleend aan het Centraal Schriftelijk Examen LBO 1981 en 1982. De eerste tekst was getiteld ‘Utrecht: provincie en stad’, de tweede ‘Uitwaaien op het wad’. Deze toetsen zijn in hun open vraagvorm beproefd bij 438 leerlingen uit de derde klas LBO en MAVO. Op grond van de foute antwoorden van deze leerlingen zijn vervolgens de afleiders (de foute alternatieven) van de vierkeuze-vragen geconstrueerd.
De vier tekstbegriptoetsen zijn (in hun definitieve versie) afgenomen bij 590 leerlingen uit de derde klas LBO en MAVO. Elke leerling maakte één van de vier toetsen. Hierbij was de toewijzing van de tekstbegriptoetsen aan de leerlingen gerandomiseerd. De antwoorden op de open vragen zijn beoordeeld aan de hand van een in het vooronderzoek ontwikkeld correctie-schema (Van den Bergh, 1987). In dit correctie-schema werd een overzicht gegeven van alle goede en foute antwoorden van de leerlingen (n = 438) uit de beproevingsfase van de tekstbegriptoetsen. De antwoorden van de leerlingen in het uiteindelijke onderzoek werden door een docent beoordeeld. De stabiliteit van deze docent bleek bevredigend (r = .91; n = 50). De antwoorden van 100 leerlingen op de open vragen zijn ook door een tweede docent beoordeeld; de overeenstemming tussen beide docenten was redelijk (r = .86; n = 100).
We presenteren eerst enkele psychometrische gegevens omtrent de vier tekstbegriptoetsen (zie tabel 1).
| Tekst |
Vraagvorm |
N |
gem |
sd |
KR-20 |
| A |
open |
167 |
15.11 |
4.09 |
.84 |
| |
vierkeuze |
129 |
16.26 |
3.15 |
.63 |
| B |
open |
149 |
14.02 |
4.08 |
.83 |
| |
vierkeuze |
145 |
17.37 |
3.57 |
.63 |
Tabel 1: Enkele psychometrische gegevens van twee tekstbegriptoetsen met open vragen en dezelfde toetsen met de vragen in meerkeuze-vorm (N = aantal leerlingen; gem = gemiddelde; sd = standaarddeviatie, KR-20 = betrouwbaarheidsschatting)
Uit tabel 1 blijkt dat de beide tekstbegriptoetsen met open vragen beduidend hogere interne consistentie bezitten dan de toetsen met de vierkeuze-vragen. Blijkbaar meten de items in open vraagvorm meer hetzelfde concept dan de items in meerkeuze-vorm. Ook | |
| |
blijkt dat de leerlingen op de toetsen met de vierkeuze-vragen hogere scores behalen dan op de toetsen met open vragen.
Beide effecten blijken voor zowel mannelijke als vrouwelijke kandidaten op te gaan: op de toetsen met meerkeuze-vragen behalen zij hogere scores dan op de toetsen met open vragen, en is de homogeniteit van de tekstbegriptoetsen met open vragen hoger (zie tabel 2.) Ook blijkt uit de in tabel 2 gerapporteerde gegevens dat vrouwelijke leerlingen in drie van de vier gevallen hoger presteren, ongeacht of het tekstbegrip met open dan wel met meerkeuze-vragen gemeten is. Echter, het verschil in gemiddelde prestatie op de toetsen met open en meerkeuze-vragen is voor de mannelijke kandidaten beduidend groter dan hetzelfde verschil voor de vrouwelijke kandidaten (zie tabel 2).
| Tekst |
Sekse |
Vraagvorm |
N |
gem. |
sd. |
KR-20 |
| A |
mnl |
open |
86 |
14.04 |
4.36 |
.72 |
| |
vrl |
open |
81 |
16.24 |
4.46 |
.76 |
| |
mnl |
vierkeuze |
72 |
16.00 |
4.21 |
.56 |
| |
vrl |
vierkeuze |
57 |
16.59 |
4.35 |
.55 |
| B |
mnl |
open |
68 |
13.83 |
4.00 |
.70 |
| |
vrl |
open |
81 |
14.17 |
4.85 |
.79 |
| |
mnl |
vierkeuze |
77 |
18.05 |
4.32 |
.63 |
| |
vrl |
vierkeuze |
68 |
16.59 |
5.22 |
.57 |
Tabel 2: Enkele psychometrische gegevens betreffende de vier tekstbegriptoetsen uitgesplitst naar sekse (N = aantal leerlingen; gem. = gemiddelde; sd. = standaarddeviatie; KR-20 = betrouwbaarheidsschatting)
| |
3 Resultaten
Voor de analyse van de verschillen in prestaties van mannelijke en vrouwelijke LBO- en MAVO-leerlingen op tekstbegriptoetsen met open en vierkeuze-vragen is gebruik gemaakt van loglineaire modelpassing. Per tekst per item is een kruistabel geanalyseerd met drie dimensies: de leesvaardigheid (Li) met drie niveaus: (relatief) hoog, gemiddeld, en laag leesvaardige leerlingen; de sekse van de leerling (Sj) met twee niveaus: mannelijk en vrouwelijk; en als afhankelijke variabele het Antwoord van de leerling (A) met twee niveaus: het item goed (g) en het item fout (f) beantwoord. De prestaties op een item kunnen volledig beschreven worden met het logit-model:
P(Ag/Af) = C + Li + Sj + LSij)
In dit model (1) is het antwoord van een leerling afhankelijk van een Constante (C), zijn Leesvaardigheid (Li), zijn Sekse (Sj) en de interactie tussen Leesvaardigheid en Sekse (LSij). Indien een item niet biased (zuiver) is, is het correct beantwoorden van een vraag niet afhankelijk van de sekse van een leerling en mogen de termen waarin de variabele Sekse (Sj) een rol speelt uit het model verwijderd worden zonder dat dit resulteert in een (significant) slechtere passing: de termen Sekse (Sj) en Leesvaardigheid x Sekse (LSij) kunnen dan verwijderd worden (Mellenbergh, 1981).
| |
| |
Bij de analyse is gebruik gemaakt van een iteratieve procedure. Eerst zijn de leerlingen in drie even grote groepen (relatief hoog, gemiddeld en laag leesvaardigen) ingedeeld, waarna alle items geanalyseerd zijn. Vervolgens is het meest onzuivere item uit de set verwijderd, waarna de leerlingen opnieuw in drie groepen ingedeeld zijn, en de analyse opnieuw gestart is, etc. Deze procedure is net zolang herhaald tot géén van de resterende items meer onzuiver was tegen geslacht (i.e.G2 > 7.815, df = 3, p < 0.5).
Het zou te ver voeren alle toetsingsgrootheden van alle items te presenteren. Wij beperken ons tot de acht items waarvan de onzuiverheid tegen geslacht aangetoond kon worden. Het bleek dat zes van de 50 open en twee van de 50 meerkeuze-vragen onzuiver tegen geslacht waren. De responscurven van deze acht items zijn in figuur 1 weergegeven.
Indien er geen sprake is van een interactie-effect tussen vraagvorm en sekse (LSij), dan zouden de responscurven allen evenwijdig lopen. Sterker nog, bij de afwezigheid van een effect van sekse (Sj), zuivere items, vallen de responscurven voor vrouwelijke en mannelijke leerlingen samen. Bovendien mag verwacht worden dat de curven een monotoon stijgend verloop te zien geven, daar de (logit van de) proportie correcte antwoorden van de leerlingen uit de laag leesvaardige groep (niveau 1) lager is dan die van de gemiddeld leesvaardige groep (niveau 2), welke weer lager is dan die van de hoog leesvaardige groep (niveau 3). In figuur 1 kunnen afwijkingen van parallelliteit van de responscurven voor een item geïnterpreteerd worden als een interactie-effect van sekse x vaardigheidsniveau (LSij) en als de responscurven voor mannelijke en vrouwelijke leerlingen niet samenvallen, dan mogen we dit opvatten als een hoofdeffect van sekse (Si).
Op grond van de responscurven uit figuur 1 kan geconcludeerd worden dat alle zes de onzuivere open vragen onzuiver zijn tegen mannelijke leerlingen, immers de p-waarde van de items voor mannelijke leerlingen is lager dan de p-waarde voor vrouwelijke leerlingen van hetzelfde vaardigheidsniveau. Uit bij voorbeeld curven voor item A blijkt dat mannelijke leerlingen ongeacht hun leesvaardigheidsniveau l, 2 of 3) lager presteren op dit item. Het opvallendste verschil is bij de gemiddeld leesvaardige groep (niveau 2). De p-waarde voor de mannelijke leerlingen is .08, terwiji de p-waarde voor vrouwelijke leerlingen met een gelijk leesvaardigheidsniveau .43 bedraagt. Voorts blijkt dat de onzuiverheid van de open vragen soms veroorzaakt wordt door de laag leesvaardige groep (curven voor de items: A, B, D en G), soms door de gemiddeld leesvaardige groep (curven voor de items: A, C en F) en soms door de hoog leesvaardige groep (curven voor de items: C, D, E en H). Kortom, er lijkt een weinig systematisch verband tussen de score-groep (of de leesvaardigheid van de leerling) en de onzuiverheid van een vraag. Wel moet opgemerkt worden dat het voor het merendeel relatief moeilijke items betreft (items met een lage gemiddelde p-waarde). Van de twee onzuivere meerkeuze-vragen is er één onzuiver tegen mannelijke en één onzuiver tegen vrouwelijke leerlingen.
| |
4 Discussie
Om inzicht te krijgen in het type vragen dat onzuiver bleek, zijn alle onzuivere vragen hieronder weergegeven (de letters voor de vragen corresponderen die van de responscurven in figuur 1).
| A. | In welk jaar werd met de bouw van de Domtoren begonnen? |
| B. | Waarover schreef Wouter Paap in zijn boek? |
| |
| |
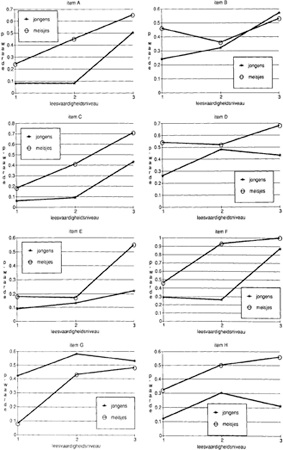
Figuur 1: De responscurven van de acht onzuivere tekstbegripvragen. Figuur A tot en met F hebben betrekking op open vragen. Figuur G en H hebben betrekking op meerkeuze-vragen (niveau = leesvaardigheidsniveau: 1 = laag; 2 = gemiddeld; 3 = hoog)
| |
| |
| C. | In welke periode wordt, volgens de tekst, de Waddenzee overgestoken? |
| D. | In welk boek staat dit? (N.B.: dit verwijst naar een hele alinea, waar de inhoud van een boek wordt samengevat). |
| E. | Waar steken wadlopers het wad over? |
| F. | ‘En zo blijft het ook’ (nr. 51). Waarnaar verwijst ‘het’? |
| G. | In Utrecht zijn veel actiegroepen. Waar protesteren die actiegroepen tegen?
| 1. | De actiegroepen protesteren tegen de milieuvervuiling, die in Utrecht grote vormen aanneemt. |
| 2. | De actiegroepen protesteren tegen de aanleg van nog meer wegen. |
| 3. | De actiegroepen protesteren tegen de wegen in Utrecht, omdat er al teveel wegen door de provincie lopen. |
| 4. | De actiegroepen protesteren tegen de luchtvervuiling, die door de auto's veroorzaak wordt. |
|
| H. | Wat wordt in de tekst bedoeld met ‘reuzekrakelingen’ (r. 10)?
| 1. | Met reuzekrakelingen worden de vele wegen en de brede autowegen in de provincie Utrecht bedoeld. |
| 2. | Met reuzekrakelingen worden kunstwerken van asfalt langs de snelweg bedoeld. |
| 3. | Met reuzekrakelingen worden weg- en waterbouwkundige voorzieningen bedoeld. |
| 4. | Met reuzekrakelingen worden kruisingen en snelwegen in de vorm van klaverbladen bedoeld. |
|
Delen we de bovenstaande vragen in naar het type vragen, volgens de door het CITO gebruikte toetsmatrijs voor examenvragen (Kreeft, 1985), waarin betekenisvragen, relatievragen en communicatievevragen onderscheiden worden, dan blijken alle onzuivere vragen zogenaamde relatievragen te zijn. Dat wil zeggen: in de vraag wordt één element en een vraagwoord dat de relatie aanduidt gegeven. Geen van de vragen blijkt in zowel zijn open als gesloten vraagvorm onzuiver tegen geslacht. Het is daarom niet waarschijnlijk dat de onzuiverheid van de vragen veroorzaakt wordt door de wijze waarop deze geformuleerd zijn. Om dezelfde reden lijkt de vraagonzuiverheid niet gerelateerd aan de tekst waarbij de vraag gesteld is.
De vraag blijft dus waarom deze open tekstbegripvragen vaker onzuiver zijn tegen mannelijke leerlingen dan dezelfde vragen in gesloten toetsvorm. Ten aanzien van de in de inleiding geopperde hypothesen kunnen we het volgende opmerken. Daar geen van de open vragen zowel in open als meerkeuze-vraagvorm onzuiver tegen geslacht bleek moeten de verschillen in de beantwoording van open en meerkeuze-vragen door mannelijke en vrouwelijke leerlingen in de wijze van antwoorden gezocht worden en niet in de formulering van de vraag. Een hypothese die hierop aansluit is, dat de open vragen onzuiver zijn tegen mannelijke kandidaten, omdat die minder formuleervaardig (zouden) zijn dan vrouwelijke leerlingen. Deze verklaring lijkt minder waarschijnlijk daar alle onzuivere open vragen korte-antwoord vragen waren. Een correct antwoord kon, afhankelijk van de vraag, bestaan uit één tot enkele woorden. Omdat er bij de beantwoording van de onzuivere vragen volstaan kon worden met hooguit enkele woorden, is het evenmin aannemelijk dat het handschrift van de leerlingen een overheersende factor heeft gevormd.
Op grond van de resultaten van dit onderzoek kunnen we concluderen dat tekstbegriptoetsen met vragen in meerkeuze-vorm minder betrouwbaar zijn dan tekstbegriptoetsen met dezelfde vragen in open vorm. De interpretatie van de lagere betrouwbaarheidsschattin- | |
| |
gen voor de gesloten tekstbegriptoetsen lijkt vrij eenvoudig. Een betrouwbaarheidscoeëfficiënt geeft aan welke proportie van de waargenomen variantie ware score variantie is, m.a.w. een betrouwbaarheidscoëfficiënt geeft aan hoe goed er een onderscheid gemaakt kan worden tussen leerlingen op grond van de geobserveerde score. Een gerechtvaardigde aanname is dat met name zwakkere lezers profiteren van de gesloten toetsvorm. Immers, deze leerlingen weten het antwoord op (relatief) veel vragen niet en zullen naar deze antwoorden ‘raden’, waarvan zij er altijd wel een aantal goed ‘raden’. Het gevolg is, dat de verschillen in geobserveerde score tussen goede en slechte lezers kleiner worden. Er kan dan minder goed een onderscheid gemaakt worden tussen goede en slechte lezers, hetgeen tot uiting komt in een lagere betrouwbaarheidsschatting.
We hebben in het bovenstaande het woord raden tussen aanhalingstekens geplaats. De reden hiervan is, dat het onduidelijk is of de leerlingen die een antwoord niet weten echt raden (een willekeurig alternatief aanstrepen), of dat zij een meer geavanceerde strategie toepassen door bij voorbeeld eerst de meest onwaarschijnlijke antwoorden weg te strepen.
Ook is gebleken dat het verschil in prestaties van mannelijke en vrouwelijke leerlingen op gesloten tekstbegriptoetsen kleiner is (of zelfs tegengesteld) aan dat van de gemiddelde prestaties op open tekstbegriptoetsen. Tot slot is (bij een beperkte steekproef leerlingen en vragen) gedemonstreerd dat open tekstbegripvragen vaker onzuiver zijn tegen geslacht dan meerkeuze-tekstbegripvragen; open vragen tekstbegrip lijken vrouwelijke kandidaten te bevoordelen. Dit ‘voordeel’ is echter zeer gering. Binnen de drie onderscheiden groepen (laag, gemiddeld en hoog leesvaardiger) scoren de vrouwelijke leerlingen respectievelijk 0.8, 1.2 en 1.2 punten hoger.
Wat is nu het praktisch belang van vraagonzuiverheid voor de toetspraktijk in het CSE? Voor ons antwoord moeten we drie veronderstellingen maken. Ten eerste veronderstellen we dat in een eindexamen, evenals in dit onderzoek, gemiddeld 10% van de open vragen onzuiver tegen geslacht is, en dat de gemiddelde onzuiverheid van de onzuivere vragen .2 is. Ten derde gaan we ervan uit dat de toets die in het CSE 1987 voor MAYO-Ckandidaten gebruikt is representatief is voor het ‘nieuwe’ CSE. Voor deze toets, waarbij 47 vragen gesteld werden, konden de kandidaten maximaal 50 punten behalen, hiervan konden zij 15 punten (30%) behalen met de beantwoording van de open vragen. De betrouwbaarheidsschatting (KR-20) van deze toets was .64. Een schatting voor de gemiddelde ware score van mannelijke kandidaten
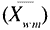
kan uitgedrukt worden als functie van de gemiddelde geobserveerde score van mannelijke kandidaten
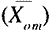
, het aantal onzuivere vragen (P o), het aantal punten dat met beantwoording van de open vragen behaald kon worden (O p), en de mate waarin de vragen biased zijn (b g).
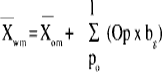
(2)
Substitutie van de gevonden resultaten en de gegevens uit het Centraal Schriftelijk Examen tekstbegrip levert de geschatte gemiddelde ware score van mannelijke kandidaten. Deze bleek 30.3. Dit verschil tussen de (gemiddelde) geobserveerde en (gemiddelde) ware score is marginaal, zeker als we bedenken dat de standaardmeetfout 3.38 is. Teruggebracht op een tien puntsschaal bedraagt het verschil tussen het geobserveerde en geschatte gemiddelde van mannelijke kandidaten ongeveer .01 punt.
Concluderend: er is bij een relatief kleine steekproef leerlingen uit de derde klas van het LBO en MAVO aangetoond dat meerkeuze-vragen minder vaak onzuiver zijn tegen | |
| |
sekse dan dezelfde vragen in open vraagvorm. Hierdoor hebben we aanleiding om te veronderstellen dat het oplossingsproces zoals dat bij open en meerkeuze-vragen bij leerlingen plaats vindt niet geheel identiek is.
Tot slot willen we opmerken dat item bias vooralsnog vooral theoretisch van belang lijkt. In de huidige examenpraktijk, zal de invloed van onzuivere items niet of nauwelijks merkbaar zijn, gezien de matige betrouwbaarheid van de examentoetsen; gemiddeld over een aantal jaren en schooltypen (LBO en MAVO) is de gemiddelde betrouwbaarheid van 20 open vraag examens .53.
Bibliografie
|
| Bergh, H.van den, Oude en nieuwe examens vergeleken: instrument constructie (interimrapport: SVO-project: 4075). SCO, Amsterdam, 1987 |
| Bolger. N, Gender differences in academic achievement testing according to method of measurement. Paper presented at: the 92nd convention of the American Psychological Convention, 1984 |
| Campbell, D.T. & D.W. Fiske, Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56, 1984, p. 81-105 |
| Cook, T.D. & D.T. Campbell, Quasi-experimentation: design analysis issues for field settings. Rand McNally, College Publishing Company, Chicago, 1979 |
| Fiske, D.W., Construct invalidity comes from method effects. Educational and Psychological Measurement, 47, 1978, 285-307 |
| Forrest, G.M., Standards in Subjects at the Ordinary level of the GCE, June 1970, JMB, Manchester, 1971 |
| Forrest, G.M. & G.A. Smith, Standards in Subjects at the Ordinary level at the GCE, June 1971, JMB, Manchester, 1972 |
| Jensen, A.R., Bias in mental testing. Methuen, London, 1980 |
| Knops, W., Tabellen met psychometrische gegevens van open vragen examens vanaf 1978. CITO, Arhnem 1983 |
| Kreeft, H.P.J., Een beschrijvingsschema voor tekstbegripvragen. CITO, Arnhem, 1985 |
| Linn, R.L., Fair test use in selection. Review of Educational Research, 43, 1973, p. 139-161 |
| Mellenbergh G.J., Conditional item bias methods. Psychologisch Laboratorium van de UvA, Amsterdam, 1981 |
| Modgil, S. & C. Modgil, Arthur Jensen: Consensus and controversy. The Falmer Press, New York 1987 |
| Murphy, R.L., Sex differences in test performance, British Journal of Educational Research, 52, 1982, p. 213-219 |
| Nutall, D.L., J.K. Backhouse & A.S. Willmott, Comparability of Standard between Subjects. (School Council Examinations Bulletin 29) Evans/Methuen Educational, 1974 |
| Stanley, J.C., Further evidence via the analysis of variance that woman are more predictable than man. Ontario Journal of Education Research, 10, 1967, p. 49-56 |
| Willmott, A.S., CSE and GCE Grading Standards: the 1973 Comparability Study. Macmillian Education, London, 1977 |
|
|
