
Tijdschrift voor Nederlandse Taal- en Letterkunde. Jaargang 95
(1979)– [tijdschrift] Tijdschrift voor Nederlandse Taal- en Letterkunde–
[pagina 247]
| |
De ambtelijke teksten van het Corpus-GysselingOnder de reekstitel Bouwstoffen voor een Woordarchief van de Nederlandse Taal is sinds begin 1979 in de boekhandel verkrijgbaar het Corpus van Middelnederlandse Teksten (tot en met het jaar 1300) uitgegeven door Maurits Gysseling. M.m.v. en van woordindices voorzien door Willy Pijnenburg. Reeks I: Ambtelijke Bescheiden. Het werk is verschenen bij Martinus Nijhoff te 's-Gravenhage. Het titelblad geeft als verschijningsjaar 1977 aan. Nog niet verschenen is reeks II, de literaire teksten en reeks III, glossen. De reeks Ambtelijke Bescheiden bestaat uit negen boekdelen met in totaal XXVII + XVII + 6609 bladzijden. De eerste vier delen (p. 1-2891) bevatten diplomatische afdrukken van de eigenlijke ambtelijke teksten, telkens voorafgegaan door een localisering en datering, een korte weergave van de inhoud, die meestal is uitgegroeid tot een regest, bijzonderheden over de bewaarplaats en het uitzicht van het origineel (eventueel over afschriften) en, waar dat pas geeft, over vroegere uitgaven van en studies over het afgedrukte document. Waar dat nodig is volgt een tekstkritisch apparaat. De teksten zijn chronologisch gerangschikt en genummerd van 1 tot 1937. Dat wil niet zeggen dat het Corpus juist 1937 afdrukken van ambtelijke bescheiden zou bevatten. Het juiste getal moet in de buurt van 2050 liggen. Enerzijds zijn er nadat de nummering al vastlag nog een vrij groot aantal (als ik goed geteld heb 117) teksten bijgekomen, die op grond van hun datering tussen de andere zijn geschoven (105a, 105b, 116a...1873a), anderzijds komen er enkele nummers zonder tekst voor. In deze gevallen gaat het om stukken (b.v. 1936, 1937) die door vroegere uitgevers ten onrechte vóór 1301 zijn gedateerd. Gysselings inleiding (p. IX-XXVII) bevat een woord vooraf (met een beknopt overzicht van de geschiedenis der onderneming, een lijst van personen, archieven en instituten die door de uitgever worden bedankt en een aantal bijzonderheden over de bij de uitgave gevolgde werkwijze), een | |
[pagina 248]
| |
lijst van verkort aangehaalde werken en een register van de schrijfcentra. De laatste vijf delen bevatten de langs automatische weg vervaardigde woordindices waarvoor Pijnenburg verantwoordelijk tekent. Het zijn er vier: een alfabetische met alle tekstplaatsen, meer dan drie en een half deel lang (p. 2892-5472), een retrograde in de rest van deel 8 (p. 5473-5792), een index naar frequentie, die het grootste (p. 5793-6314) en een naar de woordlengte, die het kleinste (p. 6315-6609) part van het laatste deel inneemt. Eigenlijk is alleen de eerste, die de plaatsen in de teksten opgeeft, een echte index; de andere zijn woordenlijsten. Pijnenburgs inleiding (p. VII-XVII) bevat enkele gegevens over de drukgeschiedenis van het werk (de automatisering heeft niet alleen de indices, maar ook het zetwerk van de teksten opgeleverd) en een bespreking van de principes die bij het vervaardigen van de indices zijn toegepast, waaruit een aantal waarschuwingen voor de gebruiker worden gedistilleerd, tenslotte ook enige opmerkingen over de automatiseringstechniek die bij de produktie van het Corpus is toegepast. Het verschijnen van de ambtelijke teksten van het Corpus-Gysseling is een van de grote gebeurtenissen in de geschiedenis van de Nederlandse taalkunde. De hele beginperiode van de doorlopende niet-literaire overlevering van onze taal kan nu onderzocht worden, wat een aanzienlijke winst moet opleveren voor de Middelnederlandse grammatica en woordenschatGa naar voetnoot1), in kwantitatief opzichtGa naar voetnoot2), maar niet minder onder verschillende aspecten van de diversiteit van het schriftelijk taalgebruik in de mnl. tijd: interne verscheidenheid van teksten, variatie in de ruimte, in de tijd, naar de tekstsoort (oorkonden, goederenlijsten, rekeningen, statuten enz.), in centra met een goede overlevering ook naar kanselarij en scribent. Hierdoor is het werk niet alleen voor de beoefenaar van de traditionele historische taalkunde aantrekkelijk, maar | |
[pagina 249]
| |
ook voor de moderne linguist wiens belangstelling vooral naar stratificaties van taalgebruik uit gaat. De grootste verdiensten in deze onderneming heeft vanzelfsprekend Gysseling, die hiermee voor de derde maal door een uiterst belangrijke en monumentale materiaalverzameling de Nederlandse filologie aan zich verplicht heeftGa naar voetnoot3). Ook Pijnenburg, die een ingewikkelde technische taak, een ware uitdaging, tot een goed einde heeft gebracht, komt alle lof toe. Er zijn echter nog twee andere filologen die in de totstandkoming van dit Corpus een aandeel hebben gehad waaraan niet kan worden voorbijgegaan. De eerste is Jozef van Cleemput, wiens werk eigenlijk door Gysseling is voortgezet. Van Cleemput had het plan opgevat, alle mnl. oorkonden tot 1300 uit te geven naar het voorbeeld van het Corpus der altdeutschen Originalurkunden bis zum Jahr 1300 van Friedrich Wilhelm, waarop hij door G. de Smet opmerkzaam was gemaakt. ‘Toen een tragisch verkeersongeval op 20 maart 1958 een einde maakte aan zijn enthousiasme, had hij reeds de meeste archieven geprospecteerd en zowat 845 oorkonden uit diverse Brugse depots gemicrofilmd’Ga naar voetnoot4). Gysseling heeft Van Cleemputs plan achteraf aanzienlijk uitgebreid door er ‘alle teksten, van welke aard ook, bij te betrekken: niet alleen oorkonden, maar ook goederenlijsten, rekeningen, ambachtskeuren, literaire teksten, enz., en niet alleen originelen maar ook afschriften uit de 13e eeuw zelf’Ga naar voetnoot4). Ten tweede is F. de Tollenaere te vermelden, die het initiatief heeft genomen om aan de tekstuitgave de indices toe te voegen en zowel deze als de uitgave van het geheel langs automatische weg te realiseren. Daardoor is weliswaar het verschijnen met een aantal jaren vertraagd, maar de hanteerbaarheid van de publikatie aanzienlijk vergroot. Eigenlijk is de uitgave pas daardoor toegankelijk geworden voor de taalkundige. De genoemde feiten illustreren dat het tot stand komen van het Corpus-Gysseling als een brokje wetenschapsgeschiedenis is te beschou- | |
[pagina 250]
| |
wen; dit wordt echter door de twee inleidingen op één uitzondering na niet bibliografisch ontsloten. Het kan dus zijn nut hebben, over de titels van een aantal publikaties uit de ‘incubatietijd’ van het werk te beschikken. In de volgende lijst zijn niet opgenomen de studies over afzonderlijke vroegmnl. documenten die in het Corpus zijn of zullen worden afgedrukt, wel publikaties met overzichten van in het Corpus verschenen of te verschijnen teksten en vanzelfsprekend ook overzichten over de stand van zaken op een bepaald ogenblik. | |
[pagina 251]
| |
De drie grote eisen die aan een werk als dit gesteld moeten worden, zijn: volledigheid, betrouwbaarheid en raadpleegbaarheid. Op de eerste twee wijst Gysseling zelf in zijn woord vooraf; de vijf delen indices zijn een poging om de derde optimaal te realiseren. Gysseling beschouwt de volledigheidseis als een ideaal dat hij heeft nagestreefd, maar dat ‘uiteraard onbereikbaar’Ga naar voetnoot5) is, doordat sommige depots moeilijk toegankelijk zijn, oorkonden op plaatsen kunnen liggen waar men ze niet verwacht, bij inventariseringen dateringsfouten werden gemaakt en bepaalde vroeger uitgegeven stukken thans onvindbaar zijn. Voor een recensent is het vrijwel onmogelijk te controleren of aan deze eis is voldaan: hij zou immers het zoekwerk moeten overdoen en daarbij voortdurend proberen over muren te klimmen waar Gysseling is voor moeten blijven staan. Ik kan dus alleen mijn indruk mededelen dat de uitgever binnen de grenzen van het mogelijke de nagestreefde volledigheid heeft bereikt. Van dit streven leggen de talrijke teksten getuigenis af die in het Corpus zijn ingeschoven nadat de nummering al vastlag; bijzonder illustratief hiervoor, maar ook voor de kans op omissies, is het geval van de grafelijke kanselarij van Holland, waar door toevoegingen achteraf het aantal stukken van 134 tot 200 is verhoogd. In één geval is Gysseling echter bewust onvolledig geweest en wel dat van de omvangrijkste administratieve tekst uit de behandelde periode, het oudste goederenregister van Oudenbiezen, waarvan hij onder nr. 295 slechts enkele uittreksels heeft gepubliceerd. De reden is dat dit register al in 1965 in zijn geheel is uitgegeven door J. Buntinx en M. GysselingGa naar voetnoot6). Daar intussen ook de indices op deze uitgave verschenen zijnGa naar voetnoot7), waardoor het goederenregister op dezelfde manier linguistisch toegankelijk is gemaakt als het CorpusGa naar voetnoot8), is er tegen deze | |
[pagina 252]
| |
werkwijze geen bezwaar. Wie echter op basis van het Corpus-Gysseling aan taalgeografie van het Middelnederlands wil doen, kan er niet buiten, dit belangrijkste Limburgse document naast het Corpus te hanteren. De volledigheidseis vertoont vier aspecten: taal (alle stukken in autochtone Germaanse schrijftaal), ruimte (het gehele Nederlandse taalgebied), tijd (alles voor 1301), aard van het document (alle ambtelijke bescheiden). In elk van die gevallen is vast te stellen dat Gysseling in zijn drang naar volledigheid eerder een neiging vertoont om de grenzen van wat er is te overschrijden dan om er binnen te blijven. Het Corpus bevat ten eerste enkele teksten in het Latijn, waar ook min of meer talrijke Nederlandse woorden of namen in voorkomen. Zij staan in het begin (nummers 1, Gent ± 1210 tot ± 1240; 20, Sint-Truiden 1261; 25, Brugge 1263 en 30, Brugge 1264 met telkens een brokje lopende mnl. tekst) of stammen uit een plaats waarvan zij het intussen verdwenen Nederlandse karakter moeten illustreren: Calais (nummers 887, 1253 en 1254). De drang om uit de alleroudste periode zoveel mogelijk te geven is zeer begrijpelijk bij een overlevering met de volgende verdeling van de nummers: tot 1250: 7; van 1251 tot 1260: 12; van 1261 tot 1270: 81; van 1271 tot 1280: 233; van 1281 tot 1290: 684; van 1291 tot 1300: 1037Ga naar voetnoot9). Het geval Calais zal in verband met punt twee, de ruimtelijke grenzen van het Middelnederlands, wel niet problematisch zijn. Wel zijn er hier problemen aan de oostkant, waarbij het Corpus weer eerder te veel dan te weinig geeft. Tegen het opnemen van drie oorkonden uit Deventer en Zutphen (nummers 1849, 1850, 1899) kan men daarbij geen bezwaren hebben: hoewel de schrijftaal van de IJsselsteden volgens sommigen ‘strikt genomen, geen mnl. meer’ isGa naar voetnoot10), hebben deze teksten | |
[pagina 253]
| |
hun taalkeuze blijkbaar aan een westelijke, ‘Nederlandse’ en niet aan een oostelijke, ‘Nederduitse’ cultuurstroom te danken, aangezien deze laatste op dat ogenblik nog niet bestaat. Hetzelfde zal wel gelden voor een viertal teksten uit het tegenwoordig Duitse Kleef (nummers 1522, 1526, 1870, 1933), zeker voor het nummer 1522. Hoewel dit volgens een uiting van de uitgeverGa naar voetnoot11) geen probleem is, ligt de zaak bij een paar Zuidnederrijnse stukken uit Heinsberg en Moers (nummers 688 en 1703) iets moeilijker. Het Corpus-Wilhelm bevat namelijk elf Keulse oorkonden in Ripuarisch-Hoogduitse schrijftaal uit de periode 1258-1275Ga naar voetnoot12). Het is dus goed mogelijk en op grond van hun taalvormen zelf ook plausibel dat de genoemde stukken van Gysseling uit 1286 en 1298 hun taalkeuze (mede?) aan een Keulse cultuurstroom te danken hebben die zich niet echt heeft kunnen doorzetten en in de veertiende eeuw door een grote zuidnoordstroom vanuit het Opperrijngebied is overspoeld. Persoonlijk ben ik blij dat de stukken uit Heinsberg en Moers in het Corpus staan. Ook wat het aspect tijd betreft geeft Gysseling zeker niet te weinig. In zijn voorwoord deelt hij mee: ‘Zeer uitzonderlijk werden ook belangrijke teksten van na die datum (31.12.1300, J.G.) opgenomen (afschriften, falsa), die zich aandienden als zijnde ontstaan in de 13e eeuw’Ga naar voetnoot13). Het is een klein tekort van deze uitgave dat de inleiding geen lijst van die teksten en evenmin een van de nummers zonder tekst bevat. Wat tenslotte de aard van het document betreft, stelden er zich bij de ambtelijke bescheiden geen problemen. Die komen er wel bij de literaire teksten. Blijkens de door Pijnenburg gepubliceerde lijstGa naar voetnoot14) zullen die nogal wat documenten bevatten die men niet direkt bellettristisch kan noemen. Hun opname in het literaire deel van het Corpus | |
[pagina 254]
| |
is echter bij een poging tot volledige publikatie zonder meer gerechtvaardigdGa naar voetnoot15). De betrouwbaarheidseis slaat ten eerste op de editie zelf, ten tweede op de toelichtingen bij de uitgegeven stukken. Het ligt in de natuur van de zaak dat de uitgave diplomatisch is. Even vanzelfsprekend zijn een aantal conventies en vereenvoudigingen in de druk, waarover het woord vooraf verantwoording aflegt. De vraag of en in welke omvang de uitgave van de teksten fouten bevat, die dan toe te schrijven zouden zijn aan haperingen in het lees-, afschrijf- of drukproces, kan alleen worden beantwoord door een paleografisch optimaal geschoold recensent die over alle mogelijke hulpmiddelen beschikt en alle uitgegeven teksten met de originelen vergelijkt, dus door niemand. Ik heb wel een paar steekproeven gedaan: de nummers 403, 1428, 1671 en 1695 heb ik met fotokopieën van de originelen uit het archief van de Commissie van Openbare Onderstand te Mechelen vergeleken. Het resultaat was zeer gunstig: ik heb in de uitgave van die stukken geen enkele fout gevonden, wel enkele dingen waarover met weinig vrucht gediscussieerd kan worden. Het zijn namelijk juist gevallen waarin Gysseling een slag om de arm houdt of dat in een discussie ongetwijfeld zou doen: staat er wanneer men de afkorting in de eerste regel van nr. 1671 oplost, wel prouiseure (vgl. p. XII: ‘Bij de keuze van de oplossing (van afkortingen, J.G.) is willekeur echter vaak niet te vermijden’), heeft Eerre in de derde regel van hetzelfde document (de vierde van de druk) wel een hoofdletter (vgl. p. XIII: ‘Toch is heel dikwijls niet uit te maken of de scribent een hoofdletter of een kleine letter bedoeld heeft...’)? In nr. 1695 lijkt mij het tweemaal aan elkaar schrijven van ontfaen (regel 25 en 26 op p. 2540) en ghenoemt (regel 30 en 31) een beetje arbitrair; het verschil met ghe noemde, dat eveneens tweemaal op dezelfde regels voorkomt, is zeker niet groot. De betrouwbaarheid van de toelichtingen bij de teksten is voor zover het om inhoudsopgaven en regesten gaat, via de teksten zelf te con- | |
[pagina 255]
| |
troleren. Mijn indruk is zeer gunstig. De gegevens over status, staat en bewaarplaats van de documenten zijn weer eens moeilijk globaal controleerbaar; fouten heb ik echter niet gevonden. Bij de localisering en datering van de documenten moesten nogal wat knopen worden doorgehakt. Daar is Gysseling nooit bang voor geweest; toch valt in de talrijke vraagtekens achter plaatsnamen en plusminustekens voor data een lovenswaardige voorzichtigheid te observeren. Dat betekent niet dat de recensent het in alle gevallen met de uitgever eens dient te zijn. Ik ben er b.v. niet zeker van dat het reeds genoemde nr. 1695 te Willebroek en niet te Mechelen is geschreven. Of, om een bekend geval te nemen, dat het nodig is de gelukkig weer opgedoken oudste Nederlandstalige Loonse oorkonde uit 1277 (nr. 203) - weliswaar met een vraagteken - van Guigoven naar Tongeren te verplaatsen. De eis van raadpleegbaarheid kan aan dit werk niet alleen door de taalkundige, maar ook door de historicus en eventueel door vertegenwoordigers van nog andere disciplines worden gesteld. Ik beperk mij tot het linguistische aspect. Het Corpus bevat materiaal ter bestudering van de vroegmnl. grammatica (klankleer en spelling, vormleer - flexie en woordvorming -, syntaxis) en woordenschat. Onder die aspecten moest het toegankelijk worden gemaakt. Zijn omvang sloot een manuele bewerking van te voren uit. De automatisering maakte echter een classificatie op verschillende manieren van de in het Corpus voorkomende woordeenhedenGa naar voetnoot16) mogelijk. Daardoor kon de gebruiker geordend materiaal ter bestudering van alle genoemde aspecten van het vroegmnl., de syntaxis uitgezonderd, worden aangeboden. Dit geldt vooral voor de alfabetische en de retrograde index. De index naar de frequentie levert vooral gegevens voor statistische onderzoekingen van de woordenschat, terwijl de linguistische betekenis van die naar de woordlengte mij gering lijkt. Aan aparte lijsten van de plaats- en persoonsnamen evenals van de heiligendagen hadden we waarschijnlijk meer gehad. Het is zonder meer duidelijk dat de indices uiterst belangrijke hulpmiddelen voor de grammaticus en de lexicoloog van het mnl. zijn. Toch valt het werken met deze lijsten niettegenstaande het handige verwijs- | |
[pagina 256]
| |
systeem lang niet altijd mee. Het is b.v. nogal frustrerend voor iemand die de lotgevallen van de / en de schrijfwijzen van de diftong in woorden als oud en zout wil onderzoeken, dat 90 bewijsplaatsen met alt en 70 met sald, salt, zald moeten worden gecontroleerd om tot de vaststelling te komen dat zij in de betekenis ‘oud’ en ‘zout’ in het Corpus ontbreken (het gaat telkens om ‘al het’ en ‘zal het’). Het valt al beter mee dat van de 29 bewijsplaatsen met soud, sout, zoud of zout er vier de betekenis ‘zout’ hebben (sout 1181,22; zout 1552,27 2027,5 2773,5) en de andere ten minste bruikbaar zijn in die zin dat zij hetzelfde verschijnsel in een ander voorbeeld, zou (het), illustreren. Het gaat hier zeker niet om extreme gevallen. Wie het voegwoord ende en zijn substantivische homograaf uit elkaar wil halen, heeft 44.855 plaatsen te controleren. Dat zal dan wel het record zijn. De voorbeelden maken duidelijk waar de moeilijkheid bij het hanteren zit: de computer kan wel opeenvolgingen van letters onderscheiden, maar tegenover de woordsemantiek is hij machteloos. Toch mogen we voor de indices zeer dankbaar zijn. De deur naar het Corpus heeft stroeve scharnieren, maar je kunt hem open krijgen.
Om te besluiten zal ik door een voorbeeld verduidelijken hoe met het Corpus gewerkt kan worden, met welke moeilijkheden men daarbij heeft af te rekenen, welke aard van resultaten ermee bereikt kunnen worden en welke desiderata voor de verdere studie van het Middelnederlands daaruit ontstaan. Het gekozen voorbeeld is de afwisseling van ie- en uu-vocalisme in liede(n)/lude(n) ‘mensen, personen’. In de alfabetische indices van het Corpus en van het Goederenregister van Oudenbiezen zijn de bewijsplaatsen van dit woord opgesomd onder de lemmata lide, liden, liede, lieden, liede[n, lieder, liedie, liide, liiden, lijden, lude, luden lůde. Ten minste één ander lemma levert ook nog materiaal op, nl. leden (vgl. plaats 92,24 uit Brugge), maar omwille van het afwijkende vocalisme is dit niet mee verdisconteerdGa naar voetnoot17). Het was ook nodig, lemmata te controleren die niets opleverden, b.v. lien, in Oudenbiezen Lude. Alle | |
[pagina 257]
| |
bewijsplaatsen van de geschikte lemmata moesten op hun betekenis worden nagegaan; daardoor moesten er een aantal als homograaf wegvallen: liden in de betekenis ‘gaan, zich bewegen’ in 1336,24 2390,10 2392,23 en in de betekenis ‘lijden’ in 628,23; liede ‘verklaarde’ in 1633,29 en 1670,22 evenals Oudenbiezen 14507, als plaatsnaam in 552,17; lieden ‘geleden’ in 371,31 en 374,13, ‘verklaarden’ in 1090,36; lijden ‘verdragen’ in 371,33; lude ‘luid, hard’ in 1342,46 1344,13 2381,16; luden ‘een klok of bel luiden’ in 24,38 107,29 107,38 2075,22 2107,3 en 2461,15. Enkele gegevens die wel de juiste betekenis hadden, moesten eveneens wegvallen: lieden in 2290,38 (in een jonger falsum) en 2649,11 (in dorso in de 14e eeuw op een document van 1299 geschreven), in Oudenbiezen lude in 16430 evenals de twee gegevens met lůde in 03921 en 03928, die alle drie uit de 14e eeuw stammen. Onbruikbaar is plaats 1249,43, omdat Gysseling niet heeft kunnen uitmaken of er liiden of luden staatGa naar voetnoot18). Er kwamen geen fouten in de indices voor in deze zin dat bepaalde opgegeven plaatsen in de teksten niet terug te vinden waren; of omgekeerd alle plaatsen van de teksten in de indices voorkomen, was uiteraard niet te controleren. Het aantal geschikte gegevens bedroeg tenslotte 568. Dit had merkelijk opgevoerd kunnen worden door bij de plaatsen met het simplex ook die van de samenstellingen te voegen. Als eerste lid treedt ons voorbeeld ten minste op in de persoonsnaam lutgart met een aantal varianten, als tweede lid - zoals met behulp van de retrograde index kan worden nagegaan - in 42 computer-samenstellingen: goiderlide, goderlide, sikerlide, ambochtlide, huesliden, andwercliede, handwercliede, goedeliede, hareliede, scuteliede, siliede, wiliede, hemliede, coepliede, harlide, aerliede, schotbaerliede, haerliede, taerliede, goederliede, kerliede, siekerliede, temmerliede, onserliede, huisliede, werclieden, handwerclieden, landlieden, aermelieden, hemlieden, onderhemlieden, ziekerlieden, aermerlieden, onslieden, honslieden, ambochtslieden, harlieder, haerlieder, goederlieder, vremderlieder, hemluden, coepluden. De 568 bruikbare simplicia moesten geordend worden met het oog op de voorgenomen aard van het onderzoek. Er werd gekozen voor de | |
[pagina 258]
| |
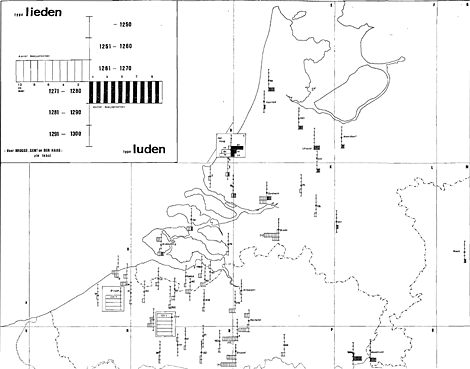
studie van de verdeling der gegevens in tijd en ruimte. Andere mogelijkheden waren geweest de tekstsoort, in centra met een goede overlevering ook kanselarij en scribent; deze hadden echter bij het besproken voorbeeld geen relevante spreiding der types opgeleverd. De localisering en datering van de stukken is weliswaar in principe door Gysseling zelf al doorgevoerd, maar zoals we gezien hebben met de nodige voorzichtigheid: er blijven bij heel wat documenten vraagtekens bestaan. Wat de tijdsparameter betreft, verdwijnen die echter bij een periodisering in de zes volgende schijven vanzelf, aangezien elk gegeven dan zonder problemen geklasseerd kan worden: tot 1250, 1251-1260, 1261-1270, 1271-1280, 1281-1290, 1291-1300. Groter zijn de moeilijkheden bij de ruimtelijke parameter. In een aantal gevallen heeft Gysseling de plaats waar het document vermoedelijk (misschien?) werd geschreven, van een vraagteken voorzien, in andere laat hij de keus tussen twee plaatsen. De voorzichtigste werkwijze zou zijn geweest, deze gegevens niet te gebruiken; ik heb daarentegen voor de omgekeerde gekozen en al deze gevallen op kaart gebracht, waarbij Gysselings vraagtekens als onbestaand werden beschouwd en in geval van meer mogelijkheden telkens voor de eerstgenoemde plaats werd gekozen. Als argument hiervoor kan worden gezegd dat deze gegevens bij de beschreven werkwijze telkens uitstekend in het kaartbeeld passen. Er moest een grondkaart worden gekozen waar de gegevens op konden worden aangebracht. Om praktische redenen heb ik de in de Nederlandse dialectologie gebruikelijke grondkaart van 1962 gebruiktGa naar voetnoot19). Dit is natuurlijk niet de principieel beste oplossing, want in de 13e eeuw liep de scheiding tussen land en water met name bij de Scheldemonding en in Noord-Holland opvallend anders dan nu. Een nieuwe grondkaart voor de historische taalgeografie van het Nederlands zou geen luxe zijn. De plaatsen waar de documenten zijn ver- | |
[pagina *1]
| |
 | |
[pagina 259]
| |
vaardigd, moesten op de kaart worden gelocaliseerd, waarbij de volgende identificaties werden doorgevoerd: Boudelo = Sinaai I 209; Brabant, hertogelijke kanselarij = Brussel P 65; Elmare = Waterland-Oudeman I 131; Holland evenals Holland, grafelijke kanselarij = Den Haag D 5; Oudenbiezen = Rijkhoven Q 168a; Ter Doest = Lissewege H 9; Vlaanderen evenals Vlaanderen, grafelijke kanselarij = Gent I 241; Zeeland = Middelburg I 81. Steenland werd op grond van de localisering van Gysseling zelf bij tekst 1080 tussen Terneuzen I 112 en Aksel I 140 geplaatst, Voorne werd met Oostvoorne I 2 en Putten met het centraal op dat eiland gelegen Spijkenisse I 18 geidentificeerd. De gegevens werden in twee klassen ingedeeld: ie-vocalisme (gespeld i, ie, ii, ij) en uu-vocalisme (gespeld u). Deze binaire verdeling werd tenslotte in kaart gebracht. Drie plaatsen hebben meer dan honderd gegevens: Den Haag 149, Brugge 122 en Gent 112. Brussel heeft er 27, alle andere plaatsen hebben er minder dan 20. Behalve voor Den Haag, Brugge en Gent zijn alle gegevens afzonderlijk in kaart gebracht en wel gespreid over een tijdsas volgens de aangenomen periodisering. Wanneer het aantal gegevens voor een bepaald type in een bepaalde plaats in een bepaalde periode meer dan tien bedraagt, zijn er slechts tien items ingetekend, daarnaast is dan echter het juiste getal afgedrukt. Dat komt driemaal voor: eens te Brussel P 65 (21 ie-gegevens voor 1291-1300), eens te Grimbergen P 4 (13 ie-gegevens voor 1291-1300) en eens te Breda (12 ie-gegevens voor 1281-1290). Voor Den Haag, Brugge en Gent is een speciale omlijnde figuur getekend, waarin de procentuele verhoudingen in elke periode zijn aangegeven. Hier volgen de absolute getallen voor die drie plaatsen: Den Haag 1271-1280: 1 ie, 6 uu; 1281-1290: 18 ie, 12 uu; 1291-1300: 85 ie, 27 uu. Brugge: uitsluitend ie-vormen, als volgt gespreid: 1261-1270: 8; 1271-1280: 9; 1281-1290: 51; 1291-1300: 54. Gent: uitsluitend ie-vormen, als volgt gespreid: tot 1250: 13; 1251-1260: 4; 1261-1270: 14; 1271-1280: 5; 1281-1290: 9; 1291-1300: 67. De kaart geeft een duidelijke ruimtelijke verdeling, die grotendeels overeenstemt met wat op grond van vroegere publikaties over de verdeling van de voortzettingen van germ. eu in het Nederlandse taalgebied | |
[pagina 260]
| |
kon worden verwachtGa naar voetnoot20). Het zuidwesten (Vlaanderen, Brabant) heeft ie-, het noorden (Noord-Holland, Utrecht) en oosten (Oost-Noord-Brabant, Nederrijn, Limburg) hebben uu-vocalisme. Zuid-Holland en Zeeland vormen een menggebied met ie en uu naast elkaar, met toch wel een overwicht van ie (in Dordrecht is de verhouding ie : uu = 10 : 3, in Middelburg 6 : 2, in Zieriksee 3 : 1, in Putten echter omgekeerd 1:2). In het menggebied levert ook het aftasten van de tijdsas een belangrijk gegeven op. Elders is die per definitie niet gevarieerd. Het geval Gent, met een goede spreiding van 112 gegevens over de gehele periode, illustreert duidelijk hoe volstrekt het ie-vocalisme er overheerst. In het menggebied zijn de gegevens van de meeste plaatsen afzonderlijk niet talrijk genoeg om verschuivingen in de tijd vast te stellen, hoewel het materiaal van Dordrecht met een verhouding 5 : 3 tussen 1281 en 1290 en 5 : 0 tussen 1291 en 1300 wel een aanduiding voor de expansie van de ie bevat. De overvloedige gegevens uit Den Haag maken echter duidelijk wat er aan de hand is: de verschuiving in de procentuele verhouding van ie en uu over de laatste drie decennia van de 13e eeuw, gaande van 14 : 86 over 60 : 40 naar 76 : 24 betekent dat in deze periode de ie de uu verdringt, globaler uitgedrukt dat er al in de 13e eeuw Vlaamse expansie in de schrijftaal van de Hollandse grafelijke kanselarij is waar te nemen. Die vaststelling mag vermoedelijk voor het hele Zeeuws-Zuidhollandse menggebied veralgemeend worden: wanneer men de gegevens voor de laatste twee decennia uit de andere plaatsen van dat areaal samentelt, krijgt men voor 1281-1290 een verhouding 6 : 4 en voor 1291-1300 11 : 5, wat tenminste tendentieel in dezelfde richting wijstGa naar voetnoot21). De kaart roept ook vragen op, waaruit desiderata kunnen worden afgeleid. Wat we in Den Haag hebben geconstateerd, zou de spits van | |
[pagina 261]
| |
een ijsberg kunnen zijn, maar om dat te weten is een statistisch onderzoek van jonger materiaal uit het Zeeuws-Hollandse gebied nodig. Wie wil weten of de ie in het zuidwesten de hele middeleeuwen door onwrikbaar blijft, moet daar eveneens materiaal uit jongere tijd statistisch onderzoeken. Het vermoeden dat de expansie van de ie zich in de 14e en 15e eeuw niet tot Zeeland en Zuid-Holland beperkt, doet eveneens een verlangen naar geordend jonger materiaal ontstaan, ditmaal uit de randgebieden met uu van de kaart. De schaarse verdeling van de gegevens over het zuidoosten en het volkomen ontbreken ervan in het noordoosten geven aanleiding tot de bedenking dat de oudste overlevering in de volkstaal voor die streken, ook al is die vele decennia jonger, even belangrijk is als de in het Corpus gepubliceerde voor het zuidwesten. Het Corpus-Gysseling doet dus een behoefte aan nieuwe materiaalverzamelingen ontstaan, waarin echter niet naar - overigens onbereikbare - volledigheid gestreefd zou dienen te worden, maar wel naar een statistisch optimale verdeling van de teksten over de parameters tijd, ruimte, tekstsoort en als het kan ook nog over de andere factoren die taalvariatie met zich mee kunnen brengen. Een zo grote concentratie van de gegevens als op de bijgevoegde kaart in het zuidwesten is daarbij niet eens nodig, wel een gelijkmatige spreiding over het hele taalgebied. J. Goossens |
|