
Spektator. Jaargang 23
(1994)– [tijdschrift] Spektator. Tijdschrift voor Neerlandistiek–
[pagina 292]
| |||||||
De mythe van het woordbeeldGa naar voetnoot*
| |||||||
Twee modellen voor lezen en spellenBeide standpunten weerspiegelen een populaire opvatting over de werking van de mentale (cognitieve) mechanismen die ons in staat stellen tot lezen en spellen. Ik zal haar aanduiden als het Dubbelkanaalmodel om de voor de hand liggende reden dat men twee ‘kanalen’ onderscheidt waarlangs woorden kunnen worden herkend of gespeld. Figuur 1 brengt dit model in beeld. 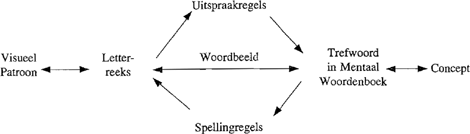
Figuur 1. Het Dubbelkanaalmodel voor lezen en spellen. Regelmatig gespelde woorden worden verwerkt via de indirecte weg (buitenom), onregelmatige via de directe weg (binnendoor).
De pijlen die naar rechts wijzen, geven aan hoe een geschreven of gedrukt woord contact maakt met een trefwoord in het Mentale Woordenboek van de lezer, dat wil zeggen als een bestaande woord wordt herkend, en hoe de beteke- | |||||||
[pagina 293]
| |||||||
nis ervan beschikbaar komt. Het eerste kanaal loopt via een component die algemene uitspraakregels toepast - regels van het soort dat u ook kunt aantreffen in leerboeken Nederlands voor anderstaligen. Omdat deze component alleen algemene uitspraakregels kent, is hij uitsluitend geschikt voor regelmatig gespelde woorden. De woorden computer en champagne zouden van een onjuiste uitspraakcode worden voorzien. Het tweede kanaal, in Figuur 1 aangeduid als ‘woordbeeld’, moet dit probleem oplossen. Men veronderstelt dat ervaren lezers en spellers associaties hebben geleerd die onregelmatig gespelde woorden rechtstreeks verbinden met hun trefwoorden in het Mentale Woordenboek, en omgekeerd. Via dit kanaal kan de juiste uitspraak van computer en champagne eenvoudigweg worden opgezocht. Ook voor regelmatig gespelde woorden die frequent voorkomen, zouden zich mettertijd dergelijke verbindingen ontwikkelen. Het woordbeeld-kanaal zorgt er ook voor dat woorden als eter en ether, eis en ijs - dat wil zeggen woorden met dezelfde uitspraak maar met verschillende spelling: niet-homografe homofonen - in het Mentale Woordenboek verschillende trefwoorden activeren. Via de pijlen van rechts naar links kan de speller op twee manieren de juiste schrijfwijze van een woord bepalen. Regelmatige spellingen komen tot stand door toepassing van algemene spellingregels, onregelmatige maken gebruik van de directe associaties. Ook hier geldt de aanname dat frequent gebezigde regelmatige woorden langzamerhand een verbinding ‘binnendoor’ krijgen naar hun schrijfwijze. Dit geldt ook voor regelmatige woorden waarvoor de algemene spellingregels meer dan één schrijfwijze zouden opleveren. Aldus weet de taalgebruiker dat faut fout is en dat bevroren water niet eis heet maar ijs. De voorstanders van spellingherziening stellen hun vertrouwen in de algemene regels. De berekening van uitspraak en spelling kost weliswaar meer tijd dan het opzoeken ervan, maar de omweg loont: alle regelmatig gespelde woorden krijgen de juiste behandeling, ook nieuwe en zeldzame. Vandaar hun voorstellen voor een spellingregeling die het aantal regelmatige woorden verhoogt. De tegenstanders zweren bij de rechtstreekse associatie tussen mentale trefwoorden en hun schrijfwijzen. Dit mechanisme voert sneller en trefzekerder tot het juiste resultaat dan regeltoepassing. Spellingvereenvoudiging verstoort vele stevig gevestigde associatieve verbanden tussen de klank en de spelling van woorden (‘regelmaat schaadt’). En zelfs bij een volmaakt regelmatige spelling kan het associatiemechanisme niet overboord gezet worden. Immers, tenzij men het radicale systeem van één-klank-één-letter zou invoeren, blijft het nodig om te kiezen tussen ou/au, ei/ij en dergelijke. Het Dubbelkanaalmodel spoort evenwel slecht met de uitkomsten van proefondervindelijk taalpsychologisch onderzoek.Ga naar eind1 Ik noem hier twee recente gegevens. Tussen haakjes, de experimenten zijn allemaal uitgevoerd met Engelse woorden en Engelstalige proefpersonen. De resultaten zal ik niettemin uitleggen aan de hand van Nederlandse voorbeelden. Er zijn geen redenen om aan te nemen dat het Nederlands essentieel andere uitslagen te zien zou geven. De oorspronkelijke gegevens zijn te vinden in Van Orden, Pennington & Stone (1990) of in daar geciteerde artikelen. | |||||||
[pagina 294]
| |||||||
Ten eerste, het lezen van volmaakt regelmatig gespelde woorden blijkt te worden bemoeilijkt door ‘nabuurwoorden’ met een onregelmatige uitspraak. Wanneer proefpersonen regelmatige gespelde woorden die eindigen op -age oplezen (bijvoorbeeld als toelage of bijdrage), wordt hun reactietijd verlengd door ‘nabuurwoorden’ waarin die uitgang anders wordt uitgesproken (zoals in garage en etalage). Woorden zonder onregelmatige naburen lopen zo'n vertraging niet op (denk aan woorden op -ame: toename, reclame). Een ander voorbeeld: regelmatige woorden op -lijk (gelijk, ongelijk) zijn aan een soortgelijke vertraging onderhevig, gezien naburen als degelijk en eigenlijk. Woorden die eindigen op -rijk hebben dit probleem niet. Het Dubbelkanaalmodel kan dit effect niet verklaren omdat de nabuurwoorden van een te herkennen regelmatig gespeld doelwoord op geen enkele manier een rol spelen. Het tweede feit heeft betrekking op de toepassing van uitspraakregels - een berekening die meer tijd zou kosten dan het opzoeken van de uitspraak via directe associatie. Van Orden en zijn medewerkers hebben deze voorspelling onderzocht in zogenaamde lexicale-beslissingsexperimenten. Hierin hoeven de aangeboden letterreeksen niet hardop te worden voorgelezen - in feite gaat het lang niet altijd om bestaande woorden. De proefpersonen krijgen bij deze taak als opdracht te beslissen of een aangeboden letterreeks al dan niet tot een bepaalde categorie behoort. Ze maken hun beslissing kenbaar door zo snel mogelijk op een ja- of een nee-knop te drukken. Ook al hoeven de proefpersonen dus geen woord te zeggen, toch blijken klankaspecten in deze taak een belangrijke rol te spelen. Bijvoorbeeld, de beslissing ‘geen lichaamsdeel’ op schauder is lastiger dan op scheuder. (Merk op dat de visuele gelijkenis met schouder ongeveer even groot is.) Uit de reactietijden kon Van Orden afleiden dat ervaren lezers de klankkernmerken van regelmatig en onregelmatig gespelde woorden ongeveer even vroeg beschikbaar krijgen. De ‘directe’ weg kost kennelijk ongeveer evenveel tijd als de ‘indirecte’. Bestaat er voor het Dubbelkanaalmodel een alternatief dat beter in overeenstemming is met de empirische gegevens? Diverse onderzoeksgroepen zijn in de weer gegaan met lerende systemen die in staat zijn statistische verbanden op te sporen tussen elementen van invoerpatronen en elementen van uitvoerpatronen.Ga naar eind2 In dit geval gaat het om verbanden tussen letterpatronen en uitspraakpatronen. Om te leren spellen moeten ze worden blootgesteld aan een groot aantal combinaties van een reeks spraakklanken (invoer) en een letterreeks (bijbehorende uitvoer). Hieruit distilleert het een netwerk van statistische samenhangen tussen spraakklanken (fonemen of foneemgroepjes) enerzijds, en ‘grafemen’ (letters of lettergroepjes) anderzijds. Bijvoorbeeld de spellingen van de ie-klank in uiteenlopende contexten (iemand, imago, hyper, panisch, paniek, biezen, bizar, bijzonder) of de diverse klankwaarden van de letter i in combinatie met andere letters (zin, zien, rijk, reik, degelijk, matig, uit, radio, saai). De sterkte van de samenhangen wordt daarbij bepaald door de frequentie van voorkomen van de invoer-uitvoercombinaties. Na een leerfase kunnen deze systemen, gegeven de elementen van de invoer, met redelijke trefzekerheid bepalen welke elementen in het uitvoerpatroon | |||||||
[pagina 295]
| |||||||
thuishoren. Ze werken niet met de tweedeling regelmatige gevallen versus uitzonderingen. In plaats daarvan hanteren ze een glijdende schaal van zwakke naar sterke verbanden tussen invoer- en uitvoerelementen. Via dergelijke verbanden kunnen alle elementen van een invoerpatroon gelijktijdig invloed uitoefenen op de samenstelling van het uitvoerpatroon. Dit maakt het mogelijk om ‘uitzonderlijke’ combinaties van invoer- en uitvoerpatronen op dezelfde wijze te behandelen als ‘regelmatige’. (Wel gaat het leerproces trager verlopen wanneer het systeem met grote aantallen uitzonderingen wordt geconfronteerd.) Na voldoende training worden uitzonderingen in hetzelfde tempo verwerkt als regelmatige gevallen. 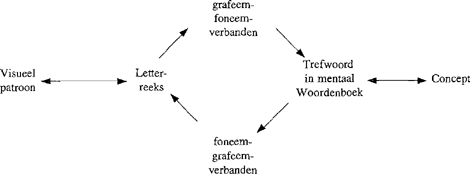
Figuur 2. Het Enkelkanaalmodel voor lezen en spellen. Onregelmatig én regelmatig gespelde woorden worden verwerkt door dezelfde modules voor grafeem-naar-foneem- en foneem-naar-grafeemomzetting.
Dit alles leidt tot het Enkelkanaalmodel afgebeeld in Figuur 2. De modules voor toepassing van algemene uitspraak- en spellingregels uit Figuur 1 zijn vervangen door modules die statistische samenhangen hebben geleerd tussen letter- en foneemreeksen (lezen) of, omgekeerd, tussen foneem- en letterreeksen (spellen). Omdat deze modules zowel de ‘regelmatige’ als de ‘onregelmatige’ gevallen aankunnen, is één kanaal voldoende. Dat een woord een regelmatige dan wel onregelmatige spelling bezit, is op zichzelf geen reden voor een snellere of tragere herkenning tijdens het lezen. Via het ene kanaal wordt de uitspraak van regelmatig gespelde woorden ongeveer even snel berekend als die van onregelmatige. Ook bovengenoemd effect van onregelmatige nabuurwoorden kan worden verklaard. De letters in -age en -lijk zullen gemiddeld zwakkere verbanden met fonemen aangaan dan die in -ame en -rijk (althans bij gelijke frequentie van voorkomen in de taal, en daarmee van aanbieding aan het lerende systeem). Het verschijnsel van niet-homografe homofonen (ijs en eis, eter en ether) levert geen probleem op voor het Enkelkanaalmodel. De statistische verbanden in de module voor grafeem-naar-foneemomzetting (woordherkenning) raken tijdens het leerproces zo fijn afgesteld dat de gelezen woordjes eter en ether in het Mentale Woordenboek twee verschillende trefwoorden oproepen, ook al is | |||||||
[pagina 296]
| |||||||
hun uitspraak dezelfde. Omgekeerd activeren deze trefwoorden in de module voor foneem-naar-grafeemomzetting twee verschillende combinaties van statistische verbanden, zodat de schrijver aan het spellingonderscheid recht kan doen. | |||||||
Woordbeelden bestaan nietWat betekent dit voor de discussie over spellingherziening? Als het Enkelkanaalmodel juist is,Ga naar eind3 beschikken we niet over een uitgebreide verzameling woordbeelden die als nevenprodukt van jarenlange lees- en schrijfervaring deel is gaan uitmaken van ons lange-termijngeheugen. De neerslag van deze ervaring is aanzienlijk slimmer en subtieler. Al lezend en spellend hebben we ons twee stelsels van statistische verbanden tussen foneempatronen en letterpatronen eigengemaakt. Ze kunnen niet alleen met bekende woorden overweg maar ook met de meeste woorden die we nog niet eerder gezien hebben. Ze zijn bovendien gedetailleerder dan de officiële spelling- en uitspraakregels, die het in specifieke gevallen immers vaak laten afweten (uitzonderingen, alternatieven). Zelfs als woordbeelden zouden bestaan, is hun belang beperkter dan vaak wordt gedacht. Molewijk (1992, p. 64) schrijft: Iemand die met het zeer opvallende woord correlatiecoëfficiënt vertrouwd is, leest dat niet eens meer, maar herkent het al van verre onmiddellijk aan de vorm en springt er als het ware gewoon over heen.Nieuw onderzoek van Marslen-Wilson, Tyler, Waksler & Older (1994) maakt deze veronderstelling evenwel uiterst twijfelachtig. Lang niet alle samengestelde woorden fungeren als trefwoorden in het Mentale Woordenboek; en ook al staan ze er in, tijdens het herkenningsproces worden ze meestal toch ontleed in hun samenstellende delen. De proefpersonen van Marslen-Wilson c.s. moesten in een lexicale-beslissingstaak zo snel mogelijk aangeven of een letterreeks al dan niet een goed Engels woord was. Ja-antwoorden moesten worden gegeven op depart, decide, vain, cover en dergelijke, nee-antwoorden op fantasiewoorden. Het bijzondere van dit experiment was dat de te beoordelen letterreeksen werden voorafgegaan door gesproken woorden. Bijvoorbeeld, vlak vóór aanbieding van depart hoorde de proefpersoon departure. De vraag was of deze auditieve stimulus de beslissingstijd zou versnellen. Dit bleek inderdaad het geval. Departure (stam+uitgang) bespoedigde de reactie op depart (alleen stam), en decision die op decide. Kennelijk activeren de gelede woorden dezelfde mentale trefwoorden als de ongelede. Dit is alleen mogelijk wanneer de gelede woorden worden ontleed tot hun onderdelen. Deze conclusie wordt versterkt door de afwezigheid van een reactieversnelling bij woordparen als apartment-apart en discover-cover. Ook al zegt de taalkundige dat apartment is opgebouwd uit de morfemen apart en -ment, dan hoeft dit nog niet te betekenen dat de gemiddelde Engelstalige lezer zich hier | |||||||
[pagina 297]
| |||||||
bewust is van een betekenisrelatie. Dergelijke morfologisch gelede woorden heten ‘(semantisch) ondoorzichtig’. In ieder geval is het Engelse apartment ondoorzichtig voor Engelstaligen, evenals discover (cover). Marslen-Wilson c.s. hebben dit in afzonderlijk vooronderzoek vastgesteld. Wel doorzichtig bleken woorden als departure (depart), decision (decide) and vanity (vain). In overeenstemming hiermee bleek dat de reactietijdversnelling uitsluitend bij ‘doorzichtige’ gelede woorden op te treden. Omdat een samengesteld woord als correlatiecoëfficiënt doorzichtig is, neem ik aan dat het wel degelijk wordt ontleed tot correlatie+coëfficiënt en niet als ‘woordbeeld’ fungeert. Omdat verreweg de meeste samenstellingen in het Nederlands doorzichtig zijn, zal ons woordherkenningssysteem ze ontleden.Ga naar eind4 Dit geldt ook voor woorden als pereboom en dorpsstraat. Het lerende systeem dat statistische grafeemfoneemverbanden moet ontdekken, zal daardoor niet geconfronteerd worden met deze woorden als geheel en niet in de gelegenheid zijn rekening te houden met hun specifieke spelling. Dit betekent dat schrijvers voortdurend de neiging zullen hebben terug te vallen op de gewone schrijfwijzen peren en dorp. Dit zal niet het geval zijn bij pruimedant en perelaar, die immers niet te ontleden zijn als peren+laar en pruimen+dant. Ook al zijn deze woorden waarschijnlijk zeldzamer dan pereboom en pruimeboom, toch voorspel ik minder fouten bij de spelling van de tussenklank: pruimedant en perelaar worden wèl gezien door het leersysteem. | |||||||
Gelijkvormigheid en analogieMet het oog op het spellingdebat is ook het volgende resultaat uit Marslen-Wilsons onderzoek opmerkelijk. De reactietijdversnelling bleek bij woordparen waar de vorm van de stam ongewijzigd blijft (departure/depart) even groot als bij paren waar de stam een verandering ondergaat (bij vanity/vain verandert de stamklinker, bij decision/decide een klinker en een medeklinker). Dit gegeven is relevant voor de beoordeling van het zogenaamde gelijkvormigheidsbeginsel in de spelling van het Nederlands: rand wordt met een -d geschreven, net als randen, ook al spreek je een -t uit. Klaarblijkelijk hanteert ons Mentale Woordenboek een nogal abstracte omschrijving van de uitspraak van trefwoorden, zodat systematisch in de taal voorkomende varianten zoals decide/decision (vergelijk ook collide/collision, erode/erosion) er moeiteloos in te passen zijn. Overgebracht naar het Nederlands houdt dit in dat het gesproken woord randen even gemakkelijk het mentale trefwoord voor rand (uitgesproken met -t) activeert, als kanten dat doet voor kant. De d/t-afwisseling in de uitspraak van rand/randen doet er niet toe. De gegevens van Marslen-Wilson c.s. maken aannemelijk dat dit ook geldt voor het lezen. Anders gezegd, het gelijkvormigheidsbeginsel lijkt als maatregel om de taak van ons woordherkenningssysteem te verlichten overbodig. Op het eerste gezicht lijkt deze conclusie in strijd met de bevindingen van Van Heuven (1991) in het volgende leesexperiment. Hij liet Nederlandstalige proefpersonen woordparen zien waarvan het ene lid een enkelvoudig, het an- | |||||||
[pagina 298]
| |||||||
dere een meervoudig zelfstandig naamwoord was. Hun opdracht luidde: beoordeel zo snel mogelijk of de twee woorden vormen zijn van hetzelfde zelfstandige naamwoord. Van Heuven vond dat woordparen als bord/borden en broek/broeken significant snellere reactietijden opleverden dan buis/buizen en druif/druiven. Hij concludeerde dat het gelijkvormigheidsbeginsel, dat in de laatste categorie woorden wordt geschonden, het leesgemak wel degelijk bevordert. Hoe valt deze uitkomst te rijmen met die van Marslen-Wilson? De oplossing is niet moeilijk. De proefpersonen van Van Heuven moesten met ja reageren als ze twee vormen van hetzelfde woord zagen. Deze beslissing werd vertraagd door een tendens om nee te antwoorden in reactie op het zien van twee verschillende medeklinkers (f/z, s/z). In de leestaak van Marslen-Wilson c.s. was expliciete beoordeling van spellinggelijkenis of -verschil niet aan de orde. Omdat het bij lezen aankomt op woordherkenning en niet op bewuste beoordeling van spellingaspecten, acht ik de uitkomsten van Marslen-Wilson c.s. méér representatief voor het alledaagse leesproces dan die van Van Heuven. Maar al kan het gelijkvormigheidsbeginsel het lezen niet bevorderen, zou het dan spelfouten kunnen tegengaan? Dit lijkt onwaarschijnlijk als men in aanmerking neemt dat de foneem-naar-grafeemomzetter in Figuur 2 op dezelfde manier leert als de grafeem-naar-foneemomzetter. Wanneer systematische spellingvarianten zoals de d/s-afwisseling in decide/decision geen probleem opleveren bij het lezen, verwacht men bij het spellen geen probleem ten gevolge de f/v-afwisseling in druif/druiven. In dezelfde bijdrage rapporteert Van Heuven tevens een opvallende uitkomst met betrekking tot het analogieprincipe in de spelling van het Nederlands. Dit beginsel, dat in belangrijke mate debet is aan ‘de tragedie der werkwoordsvormen’, ligt ten grondslag aan het onderscheid hij wordt versus ik word, analoog aan het contrast tussen hij loopt en ik loop. Het wordt verdedigd met onder meer als argument dat het de syntactische opbouw van zinnen helpt ontrafelen. Neem bijvoorbeeld een bijzin als...dat de kolonel zijn hond eraan gewend te gehoorzamen naar het asiel heeft gebracht. Men zou verwachten dat het niethoorbare maar wel zichtbare verschil tussen gewent (persoonsvorm) en gewend (voltooid deelwoord) de lezer stuurt in de richting van de juiste syntactische ontleding, met eraan gewend te gehoorzamen als een nabepaling bij hond (vergelijk...die eraan gewend was te gehoorzamen...). De leesproef van Van Heuven toont echter aan dat dit niet het geval is. Hiermee wordt ook het analogieprincipe onderuitgehaald. Als het analogiebeginsel al leesvoordeel oplevert, is dat uitermate gering en bij lange na niet opgewassen tegen het onbetwiste nadeel van moeilijke leer- en toepasbaarheid. | |||||||
Spellingherziening?De ontwerpers van onze spelling hebben enkele keuzen gemaakt die, achteraf bezien, taalpsychologisch weinig verantwoord blijken. Ik doel niet alleen op de gelijkvormigheids- en analogieprincipes maar ook op het naast elkaar bestaan | |||||||
[pagina 299]
| |||||||
van voorkeur- en toegelaten spellingen. Wie er stelselmatig naar streeft de voorkeurspelling te hanteren, heeft last van de toegelaten spellingen die hij onder ogen krijgt. Niet omdat deze zijn woordbeelden ontregelen - die bestaan immers niet - maar omdat het statistisch leersysteem er informatie aan ontleent die bestaande verbanden tussen uitspraak en voorkeurspelling verzwakt. Het uitgangspunt zou dus moeten zijn: één-woord-één-spelling. Wat betekent dit voor de verbindingsklank in samengestelde woorden? Ons woordherkenningssysteem kan er niet omheen doorzichtige samenstellingen te ontleden. Dit betekent dat het statistisch leersysteem niet of nauwelijks beïnvloed zal worden door wijzigingen in de spelling van de verbindingsklanken (niet pereboom maar perenboom, niet dorpsstraat maar dorpstraat). Het ziet immers alleen de onderdelen, niet de samengestelde woorden. Om het leerproces niet onnodig te vertragen verdient het aanbeveling de schrijfwijze van woorden als lid van een samenstelling niet te laten afwijken van hun verschijningsvorm als zelfstandig woord. Dus, omdat peren dezelfde uitspraak heeft als het eerste lid van pereboom, schrijf in beide gevallen hetzelfde. Dit leidt tot perenboom en dorpstraat (de verbindings-s is immers niet hoorbaar). Deze afspraak geeft geen uitsluitsel in gevallen waar zowel het enkelvoud als het meervoud uitgaat op een ‘stomme e’ zoals schade(n), ronde(n) en bijdrage(n). Wanneer zulke woorden als eerste lid van een samenstelling optreden, verdient de spelling zonder meervouds-n de voorkeur (dus schadeverzekeringen niet schadenverzekering). Dit omdat deze woorden niet zelden een alternatieve meervoudsvorm op -s hebben (schades, rondes). Is vereenvoudiging van de spelling van vreemde woorden (regularisering) aanbevelenswaardig vanuit taalpsychologisch perspectief? Hoe regelmatiger en eenduidiger de verbanden tussen spelling en uitspraak zijn, des te makkelijker zal het statistisch leersysteem zich van zijn taak kwijten. Maar naarmate het leerproces vordert, zullen de moeilijkheidsgraden van regelmatig en onregelmatig gespelde woorden elkaar steeds dichter benaderen. Het ‘Regelmaat baat’ geldt dus voornamelijk voor beginnende, minder ervaren lezers en schrijvers. Wie veel leest en schrijft zal zich alleen bij zeldzaam gebezigde woorden voor verrassingen geplaatst weten. Uitgaande van de alomtegenwoordigheid van redelijke programmatuur voor spellingcontrole in de nabije toekomst concludeer ik dat regularisering meer schade dan winst zal opleveren. Immers, ervaren spellers en lezers passen helemaal geen regels voor foneem-naar-grafeem- en grafeem-naar-foneemomzetting toe: ze laten zich leiden door de statistische samenhangen die het leersysteem heeft ontdekt en vastgelegd. Bij elke spellingherziening moet een groot deel van die samenhangen worden herzien (‘Regelmaat schaadt’). En dit is problematisch, hoe eenvoudig de hervormde spelling ook is. Wie hiertegen inbrengt dat het alleen maar een kwestie van wennen is, ziet een effect van blijvende aard over het hoofd. Hoe regelmatiger de verbanden tussen uitspraak en spelling, hoe groter het aantal homoniemen en daarmee het aantal keren dat het woordherkenningssysteem een lexicale ambiguëteit moet oplossen. Lezers hebben niet alleen geen last van het onderscheid tussen eis en ijs of tussen eter en ether, ze hebben er zelfs voordeel bij. | |||||||
[pagina 300]
| |||||||
Ook een mildere vorm van regularisering die streeft naar een onveranderlijke spelling van morfemen, snijdt taalpsychologisch niet altijd hout. Boven hebben we gezien dat niet alle taalkundig isoleerbare morfemen door het woordherkenningssysteem als afzonderlijke eenheden worden behandeld. De factor doorzichtigheid bleek hier de doorslag te geven. Als lezers niet doorzien, bijvoorbeeld, dat vakantie hetzelfde morfeem bevat als vacature en vacant, zijn zij niet gebaat bij regularisatie van de spelling van de k-klank in die woorden. Handhaving van de geldende voorkeurspelling verdient in zulke gevallen de voorkeur. De voor regularisering bestemde financiële middelen kunnen beter worden besteed aan verbeterde methoden voor grammatica-, spelling- en schrijfonderwijs.Dit kan tevens de tragedie van de werkwoordsvormen verlichten. * * * In debatten over spellingherziening leggen taalpsychologische motieven heel wat gewicht in de schaal. Toch zullen ze tegenover zwaarwegende economische en historische argumenten niet gemakkelijk de doorslag geven. Dit is evenwel geen excuus om recente bevindingen uit het experimenteel onderzoek naar de cognitieve processen tijdens lezen en spellen links te laten liggen en te argumenteren op basis van begrippen en theorieën die als mythen ontmaskerd zijn. | |||||||
Literatuur
| |||||||
[pagina 301]
| |||||||
Gerard Kempen Vakgroep Functieleer en Theoretische Psychologie Rijksuniversiteit Leiden Postbus 9555 2300 RB Leiden |
|