
De Gids. Jaargang 173
(2010)– [tijdschrift] Gids, De–
[pagina 344]
| |
Richard Rogers
| |
[pagina 345]
| |
vrienden. Dit maakt het onder meer mogelijk om de smaak van twee vriendengroepen met elkaar te vergelijken. Welke televisieprogramma's zijn favoriet bij de vrienden van Barack Obama? En in hoeverre verschillen die van de vrienden van John McCain? Een tweede voorbeeld dat hier aan de orde zal komen is Leaky Garden (www.leakygarden.net). Deze tool toont voor een specifieke gebruikersnaam een lijst van online diensten waar de betreffende gebruiker lid van is (zoals Twitter, Facebook en MySpace) en genereert zo een metaprofiel voor een gebruiker. | |
Post-demografisch onderzoek: van leeftijd naar lievelingsboekHet voorvoegsel post- in post-demografisch onderzoek benadrukt een conceptueel verschil met gevestigde benaderingen in het publieksonderzoek, waarin demografische categorieën zoals leeftijd, geslacht, opleidingsniveau, etniciteit en woonplaats veelal als organiserend principe dienen: het zogenaamde doelgroepdenken. Daarnaast wil het ook een bredere verschuiving markeren in de wijze waarop demografisch onderzoek voor politieke en bestuurlijke doeleinden wordt gebruikt: van de ‘bio-politieke’ toepassingen van demografie (het besturen van belichaamde subjecten) naar de ‘informatie-politieke’ doelstelling van post-demografie (het aanbevelen of sturen van informatie aan een bepaalde groep gebruikers). Post-demografisch onderzoek kijkt niet naar de traditionele demografische gegevens, maar juist naar post-demografische data zoals hobby's, helden, favoriete merken en lievelingsboeken waarmee een gebruiker zich online profileert. Hoe kunnen deze informatiestromen worden ingezet voor sociale en culturele analyse? Daarnaast legt post-demografisch onderzoek een methodologisch verschil bloot tussen twee soorten onderzoekers, tussen demografen en zogenaamde profilers. Demografen in deze zin werken over het algemeen met ‘schone’ data: officiële data (geboortes, sterfgevallen, huwelijken) en door getrainde onderzoekers via enquêtes verkregen informatie, waarbij kiezers- en opiniepeilingen bekende eindproducten zijn. Profilers daarentegen analyseren data die individuele gebruikers van online platforms uit eigen beweging aan een sociale netwerksite hebben verschaft, en maken daar vervolgens gebruik van voor onderzoeksdoeleinden. Ten slotte kan de post-demografische benadering nog onderscheiden worden van de demografische door middel van het idee van ‘digital natives’: een sociaal-cultureel begrip dat verwijst naar de generatie | |
[pagina 346]
| |
die is opgegroeid met internet, en geen ervaring heeft met handmatig bediende administratieve systemen van voor het internet, zoals kaartenbakken. De term ‘digital natives’ duidt zo een generatie aan (en is als concept gebaseerd op een bepaalde leeftijdscategorie) en past in die zin nog in een traditionele demografische aanpak. Een post-demografische benadering daarentegen is minder geïnteresseerd in de verschillen tussen generaties (zoals een digitale versus een niet-digitale generatie), maar meer in de methodes die nieuwe mediatoepassingen hanteren, bijvoorbeeld de aanbevelingssystemen waarmee sociale netwerksites vrienden, informatie, evenementen en interesses aan elkaar koppelen, op basis van gedeelde interesses, locatie of reisbestemmingen. De mogelijkheden van dit soort aanbevelingen zijn eindeloos, zolang de informatie op de platforms gedetailleerd is, goed wordt opgeslagen en lang wordt bewaard. | |
Sociale netwerksites als objecten van post-demografische studie‘Wij definiëren sociale netwerksites als websites waar gebruikers een profiel kunnen aanmaken en connecties kunnen maken tussen dit profiel en andere profielen, met het doel om een expliciet persoonlijk netwerk te creëren.’ Aldus begint een Amerikaanse studie naar het gebruik van MySpace en Facebook door tieners, uitgevoerd door het Pew Internet & American Life-project in 2007. 91 Procent van de respondenten gaf hierbij aan de sites te gebruiken om vriendschappen te onderhouden. Minder dan een kwart gebruikte de sites om te flirten. Maar hoe zit het met de niet-gebruikers van deze sites? Dit zijn gebruikers die geen lid zijn van de site maar deze wel bezoeken en die hier toegankelijke profielen bekijken. En sommigen van hen komen puur om data te verzamelen, namelijk de profilers. Ze doen dat dan wel op handmatige wijze, door de informatie scherm voor scherm op te slaan, dan wel met behulp van software en de zogeheten api (application programming interface), een toepassing die Web 2.0-platformsGa naar eind2. zoals sociale netwerksites aan derden aanbieden om dataverzameling te vergemakkelijken. Wat is nu het cruciale verschil tussen de nieuwe databanken die momenteel worden aangelegd door online diensten zoals sociale netwerksites, en de traditionele databanken? Het eerste verschil is hierboven al even aan de orde gekomen: waar de laatste zelf profielen toekennen aan personen om hen te kunnen categoriseren, genereren gebruikers van sociale netwerksites hun profielen deels zelf. Kritische intellectuelen hebben gewezen op de sluipende gevaren van een bu- | |
[pagina 347]
| |
reaucratisch systeem waarin formulieren ‘verplichte velden’ hebben, die bovendien maar ruimte bieden voor een beperkt aantal letters. Dit zou een verarming kunnen betekenen van het zelf, een van de vele manieren waarop de moderne administratieve systemen mensen tot nummers reduceren. Andere kritische commentaren op inmiddels klassieke vormen van data-analyse betoogden dat de anomalie hier het belangrijkste resultaat van analyse was. Sommige mensen (in de zin van data-constructies) zouden afsteken bij de rest, omdat ze statistisch gezien niet ‘normaal’ waren. Maar wat voor inzichten kunnen we afleiden uit de nieuwe databanken? Nog meer anomalieën? Een cruciaal verschil met de traditionele databanken is dat online platforms meer en grotere velden hebben, en daarmee veel meer mogelijkheden om jezelf te profileren. De categorie ‘Anders, namelijk...’, de laatste categorie op het traditionele formulier, die als enige ruimte liet voor taxonomische onderbepaaldheid, is hier vervangen door de categorie ‘meer’. In sommige gevallen worden gebruikers uitgenodigd om zelf een categorie toe te voegen of een zelfgeschreven notitie aan hun profiel toe te voegen, een veld voor vrije zelfrepresentatie. En nu de database je uitnodigt om je meer te uiten, rijst de vraag of een nieuwe onderzoekspraktijk mogelijk is, die aansluit op deze nieuwe post-demografische informatie. Wat zegt de manier waarop jij je profiel invult over jou? Vul je alleen de standaardvelden in? Heb je veel lege categorieën? Wat vertellen jouw interesses, en die van je vrienden, aan de profilers? | |
Jij bent wat je kijkt, leest en waar je naar luistertBij het aanmaken van een profiel wordt een gebruiker gevraagd om persoonlijke informatie in te vullen en interesses te benoemen. De standaardvelden voor geslacht, leeftijd, genoten opleidingen en locatie bestaan nog steeds, maar direct daaronder nodigt het profiel uit tot post-demografisch (zelf)onderzoek, met vragen over favoriete media-uitingen, zoals muziek, televisieprogramma's, films en boeken. Zodra het profiel ingevuld is (of tijdelijk klaar is, een profiel is nooit definitief af), begint het sociale netwerken. Je maakt vrienden (door andere gebruikers te ‘frienden’, als vriend toe te voegen), deelt informatie, voegt je bij groepen en accepteert uitnodigingen voor evenementen (vaak door aan te vinken dat je misschien komt, zoals dat op Facebook kan met de optie ‘maybe attending’). Sociaal gedrag werkt aanstekelijk en voedt zichzelf. Hoe socialer je bent, hoe prominenter je aanwezigheid op het platform, en hoe meer | |
[pagina 348]
| |
gelegenheid tot sociaal contact. Daarnaast heeft jouw activiteit zijn weerslag op de pagina's van je vrienden, die je tweets (Twitter-berichten), krabbels en commentaren lezen op jouw en hun pagina's. Het platform blijft zo activiteit aanmoedigen, door ruimte te geven voor commentaar op alles wat gepost wordt, en jou op basis daarvan meer vrienden aan te bevelen (die vrienden van vrienden zijn). Al die informatie maakt de mogelijkheden voor analyse schijnbaar eindeloos. Op praktisch en ethisch niveau zijn er echter wel grenzen aan dit type onderzoek. Praktisch gezien is er de kwestie van het verzamelen van de data, en het aanmaken van de datasets. Welke sociale netwerkdiensten laten derden toe om data te verzamelen, en in welke mate? Dan is er nog de ethische kwestie: in hoeverre en onder welke voorwaarden is het acceptabel om de door sociale netwerksites verzamelde data op te slaan, en deze vervolgens te gebruiken voor onderzoek? Het anonimiseren van de data zou een significant verschil kunnen maken, zo suggereren bepaalde ethische debatten in de sociale wetenschappen omtrent online onderzoek, al hebben wetenschappers laten zien dat anonieme data niet altijd toereikend zijn om anonimiteit ook daadwerkelijk te garanderen. Natuurlijk zijn er regels en normen voor datagebruik, met als meest basale regel dat het de instemming van de gebruiker vereist. Wie zich bij een sociale netwerksite registreert, gaat een overeenkomst aan met het platform, en om lid te kunnen worden moet je eerst akkoord gaan met de gestelde gebruiksvoorwaarden en het privacybeleid. Hierbij blijft echter tot op zekere hoogte onduidelijk wie er voor deze privacy zorg moet dragen. Je zou kunnen zeggen dat gebruikers van sociale netwerksites zelf verantwoordelijkheid op zich nemen voor privacy, omdat zij hun privacy-instellingen deels zelf kunnen kiezen. Al zijn de standaardinstellingen door het platform doordacht, de gebruiker zelf bepaalt de mate van publieke zichtbaarheid door de instelling te veranderen van ‘alleen mijn vrienden mogen mijn profiel zien’ naar ‘ook vrienden van vrienden mogen mijn profiel zien’, of zelfs ‘iedereen’ (de beschikbare gradaties binnen Facebook). Hoe ontsluiten sociale netwerksites hun data voor onderzoekers? Dit gaat via de eerdergenoemde api, die door het platform beschikbaar wordt gesteld. De api levert de simpele softwarescriptjes aan die onderzoekers in staat stellen om specifieke informatie op te vragen, bijvoorbeeld ‘toon alle vrienden voor gebruiker x’. De beschikbare scripts vallen veelal onder de privacyregeling van de sociale netwerksite, omdat de gebruiker zelf beslist of hij derden toegang geeft tot zijn persoonlijke informatie. Pas als veel gebruikers toegang verlenen tot hun informatie wordt het voor de profilers interessant. | |
[pagina 349]
| |
Een andere vorm van post-demografisch onderzoek is niet zozeer geïnteresseerd in persoonlijke informatie als wel in de relatie tussen bepaalde voorkeuren. Denk hierbij aan het aanbevelingssysteem van de online winkel Amazon die aangeeft dat een andere klant die boek x heeft gekocht ook boek y heeft gekocht. Wie die ander was is niet relevant, maar wat hij/zij verder heeft gekocht wel. Supermarkten werken met een vergelijkbare methodiek, waarbij het ook die gaat om de verzameling van producten die tezamen worden verkocht (welke frisdrank met welke chips, bijvoorbeeld). Zo kunnen ze kiezen welke producten samen voor een kortingsactie kunnen worden gebruikt, en gangbare combinaties samen in een schap zetten. | |
Post-demografische machinesTerwijl ze zichzelf niet zo beschrijven, zijn de sociale netwerksites zelf de belangrijkste machines voor post-demografisch onderzoek. Zij verzamelen de voorkeuren van hun gebruikers, ordenen deze in profielen, en ontsluiten ze voor derden, van vrienden tot profilers. Nu wil ik graag twee voorbeelden bespreken van softwaretoepassingen die boven op deze machines kunnen worden geplaatst, en ze zo inzetbaar maken voor post-demografisch onderzoek. De eerste toepassing, Elfriendo, verkent een aantal manieren waarop de profielen op de sociale netwerksite MySpace voor onderzoeksdoeleinden benut kunnen worden.Ga naar eind3. Op Elfriendo.com vul je een voorkeur in, en de tool geeft je een compleet ingevulde profielpagina, gebaseerd op de profielen van MySpace-gebruikers met diezelfde interesse. Voor de hobby ‘schaken’ levert dit een gegenereerd profiel op met als lievelingsboeken de Bijbel en het woordenboek, zie figuur 1. 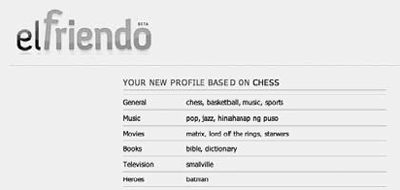 Figuur 1: Een door Elfriendo.com gesuggereerd MySpace-profiel, gebaseerd op de hobby ‘schaken’.
MySpace-gebruikers met de hobby schaken noemen op hun profielpagina's The Matrix, Lord of the Rings, Star Wars, de Bijbel en het woordenboek als favorieten. | |
[pagina 350]
| |
Ook kun je met behulp van Elfriendo vergelijken in hoeverre het ene profiel overeenkomt met het andere, door te bekijken in hoeverre verschillende voorkeuren en interesses bij elkaar passen. Hoe verenigbaar zijn christendom en islam, in de zin dat mensen die een van die twee godsdiensten hebben ingevuld naar dezelfde muziek luisteren? (Alleen de rapper Eminem komt zowel voor in het profiel van islam als dat van christendom, in een steekproef begin 2009). Elfriendo biedt een manier om dit soort vragen te beantwoorden door de profielen van groepen te analyseren, en hun interesses onderling te vergelijken. Zo kun je ook Barack Obama en John McCain invoeren, waarna de profielen van hun vrienden worden geanalyseerd op voorkeuren. De software telt de muziek, boeken, film, televisie en helden die de vrienden van beide voormalige presidentskandidaten hebben ingevuld in hun profielen. De analyse toont een groot verschil tussen de MySpace-vrienden van deze politici, ze hebben maar weinig interesses gemeen (op het gebied van films, muziek, boeken en helden delen de groepen geen enkele voorkeur, maar voor tv-programma's delen ze 16 procent, zie figuur 2). Vrienden van Obama kijken graag de Daily Show, en die van McCain geven de voorkeur aan Family Guy, Top Chef en America's Next Top Model. Beide vriendengroepen kijken graag naar de serie Lost. 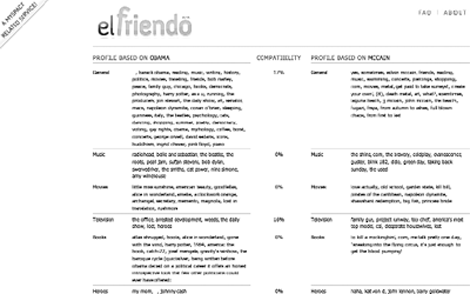 Figuur 2: De interesses van de ‘vrienden’ van Obama en McCain. Post-demografische analyse met Elfriendo.com.
Barack Obama en John McCain, de Amerikaanse presidentskandidaten van 2008, hebben ‘vrienden’ met uiteenlopende interesses. | |
[pagina 351]
| |
Ten slotte is ook het mogelijk om met behulp van Elfriendo een meer algemene vorm van post-demografisch onderzoek te verrichten, in de zin dat het zich richt op de populatie gebruikers van een site als geheel. In de conclusie van dit stuk geef ik vast een suggestie voor hoe dit soort onderzoek in de toekomst toegepast zou kunnen worden, door de principes uit kijkcijferonderzoek toe te passen op sociale netwerksites. | |
Het Leaky Garden-projectOm goed te werken moeten sociale netwerken niet alleen mensen insluiten maar ook uitsluiten. De sociale netwerksite Facebook wordt ook wel beschreven als een walled garden, een ommuurde tuin. De term verwijst naar de manieren waarop Facebook bepaalde diensten binnen het platform aanbiedt, om ervoor te zorgen dat gebruikers het platform niet verlaten. Zo werkt Facebook met plug-ins voor Flickr (een online platform voor het delen van foto's) en Twitter (een online platform voor het publiceren van korte berichtjes). Sociale netwerksites, en Facebook in het bijzonder, moedigen daarmee ook het gebruik van het platform door andere commerciële partijen aan, vanuit de nieuwe-mediagedachte dat niet alleen de inhoud maar ook de toepassingen van het platform het niveau en de waarde van gebruikersparticipatie - en dus van het platform - zullen doen toenemen. De tool Leaky Garden geeft een nieuwe dimensie aan post-demografisch onderzoek.Ga naar eind4. Gebouwd boven op de service usernamecheck, die de beschikbaarheid van een gebruikersnaam controleert voor een lange lijst Web 2.0-applicaties. Usernamecheck.com is een handige dienst. Als je een nieuwe gebruikersnaam overweegt, wil je wellicht eerst weten op welke platforms deze nog niet in gebruik is. Voor het Leaky Garden-project is usernamecheck echter omgebouwd tot een profileermachine. Op Leakygarden.net voer je een gebruikersnaam in en je ziet voor welke platforms en diensten die gebruiker zich heeft geregistreerd.Ga naar eind5. Wat zegt die lijst over de betreffende gebruiker? Als iemand Flickr- en YouTube-accounts heeft kan dit een bepaalde affiniteit met beeld betekenen, heeft diegene een LinkedIn-profiel dan suggereert dit bepaalde professionele aspiraties, is iemand vooral actief op Last.fm en MySpace, dan zegt dat wellicht iets over de rol die muziek in zijn/haar leven speelt. Deze lijst van applicaties waar een gebruiker zich voor heeft geregistreerd laat zich dus lezen als een metaprofiel (een profiel van profielen), zie figuur 3. | |
[pagina 352]
| |
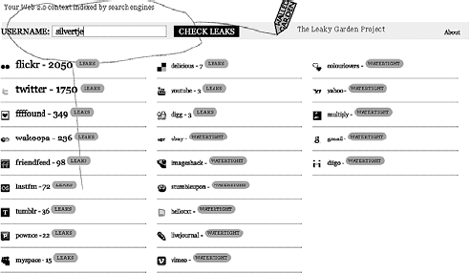 Figuur 3: De persoonlijke context van een internetgebruiker, afge- beeld door Leakygarden.net.
De internetgebruiker Silvertje (een alias) is geregistreerd voor de genoemde online diensten. Voor elke dienst toont Leakygarden.net het aantal publiek toegankelijke items dat is geassocieerd met de gebruiker Silvertje. | |
What would Nielsen do?Twee methoden domineren het publieksonderzoek in de oude audiovisuele media, het handgeschreven logboek van de televisiekijker of radioluisteraar, en de automatische meter die registreert hoe lang een televisie of radio aanstaat per huishouden (of lid van een huishouden). Baanbrekend in de ontwikkeling van deze methoden was het Amerikaanse bedrijf Nielsen. Nog altijd stuurt Nielsen viermaal per jaar een enquêtepakket naar geselecteerde families in de Verenigde Staten, om hun kijkgedrag vast te leggen gedurende zogenaamde ‘sweeps weeks’ (meetweken). Elke deelnemer vult demografische gegevens in en houdt een lijst bij van bekeken televisieprogramma's. Vervolgens kunnen er gerichte reclames worden geprogrammeerd, toegespitst op de demografie van de kijkers van een bepaald programma (zoals een dagelijkse soapserie). De logboekmethode heeft echter te lijden onder zogenaamde logeffecten, het feit dat mensen hun kijkgedrag aanpassen als ze weten dat het wordt vastgelegd, en om deze reden geniet een geautomatiseerde methode soms de voorkeur. In de Verenigde Staten werd dat soort registratieapparatuur in eerste instantie ontwikkeld voor radioluisteraars, met de introductie van de Nielsen Audimeter in de jaren veertig. De Audimeter hield bij op welke frequentie de radio was afgestemd en voor hoe lang. De resultaten waren destijds al bruikbaar voor adverteerders, en dat zijn ze nog altijd. Over de allereerste me- | |
[pagina 353]
| |
ting met de Audimeter in 1942 schreef Time Magazine destijds: ‘Vlak nadat de ster van een van de meest populaire avondprogramma's “Good night” had gezegd, kelderde het aantal luisteraars dramatisch. De afsluitende commercial van de sponsor werd dus slechts door een fractie van de luisteraars gehoord’ (Time Magazine, 1943). Nielsens geautomatiseerde kijkcijfermetingen begonnen in de jaren vijftig en werden naar een hoger plan getild met de Storage Instantaneous Audimeter, een zwarte doos die het kijkgedrag per televisietoestel in huis kon vastleggen en de data dagelijks via een telefoonlijn verzond naar het hoofdkantoor. In de jaren tachtig zijn ook persoonlijke meters ontwikkeld, waarbij elk lid van het huishouden een eigen knop op de afstandsbediening kreeg. Achter de knop, in de database, bevond zich de demografische informatie met geslacht en leeftijd van de kijker, en de meter op het toestel werd gekoppeld aan de desbetreffende locatie. Televisieprogramma's kregen een eigen puntensysteem, met telkens één punt voor een percentage huishoudens dat keek. De advertentietarieven werden gerelateerd aan deze kijkcijfers en uitgedrukt in kosten per punt. Een show heeft een verwacht kijkcijfer (gebaseerd op cijfers uit het verleden) en een werkelijk kijkcijfer. Voor adverteerders werd het natuurlijk interessant om achteraf te bekijken of de advertentie een goede koop was, en de advertentie wellicht meer kijkers (en de ‘juiste’ doelgroep) had bereikt dan verwacht.Ga naar eind6. Zou post-demografisch onderzoek de ambitie moeten hebben om de machines en metingen van Nielsen en het daarop gebaseerde kijkcijferonderzoek te evenaren? Zijn er post-demografische equivalenten van kijk- en luistercijfers? Het is mogelijk om de kijkcijfermethode van het televisieonderzoek toe te passen op sociale netwerksites, door de interessevelden en demografische gegevens op te tellen. Zo kun je voor een bepaalde netwerksite in zijn geheel specifieke interesses in kaart brengen, zoals ik en mijn collega's voor Hyves hebben gedaan in 2007 (maar zonder hierbij demografische gegevens te gebruiken), zie figuur 4. Onder de interesses van Hyvers staan onder andere favoriete merken, die Hyvers invullen op hun profiel (maar niet met de ijver en precisie die van de Nielsen-proefpersonen werd gevraagd). Voorbeelden van Hyvers die op onconventionele wijze het ‘merken’-veld invullen: My Style is My Brand | |
[pagina 354]
| |
 Figuur 4: De 50 meest populaire merken op Hyves. Een voorbeeld van post-demografische analyse van de Nederlandse sociale netwerksite.
Deze ‘brand cloud’ (merkenwolk) toont de populairste merken onder Hyves-gebruikers. Deze 50 merken worden het meest genoemd in profielen van ‘Hyvers’. Daar doe ik dus ff lekker niet aan mee he Hoe kun je deze informatie opschonen en tot bruikbare datasets transformeren? What would Nielsen do? Je zou de kijkcijfermethode kunnen toepassen op het nieuwe medium. Misschien zouden sommige Hyvers wel deel willen nemen aan Nielsens ‘sociale netwerkers’-onderzoek, en het bedrijf brandschone kersverse profielen kunnen leveren. De velden zouden dan in de gaten kunnen worden gehouden door Nielsen, die veranderingen in interesses en voorkeuren stelselmatig zou opslaan. Waarderingen (zoals bijvoorbeeld de ‘like’-button op Facebook) zouden van een puntensysteem kunnen worden voorzien, waarbij fans het equivalent zouden kunnen worden van kijkers. Dit voorstel klinkt wellicht onwaarschijnlijk, maar verwijst naar de grotere vraag of (en zo ja wanneer) standaard onderzoeksmethoden kunnen worden geïmporteerd in een nieuw medium, en wanneer we dat vooral niet moeten doen. Het zet ons ook aan het denken over innovatieve toepassingen van post-demografisch onderzoek die juist breken met de traditie. |
|