
Tabu. Jaargang 15
(1985)– [tijdschrift] Tabu–
[pagina 79]
| ||||||||||||||||||||||||||||||||||||||||||||||
Een computerlinguistische vingeroefening: VUN (Voorspelling Uitspreekbaarheid Nonsenswoorden)
| ||||||||||||||||||||||||||||||||||||||||||||||
| (1) | a. | blast, dest, momp, glurk |
| b. | lbast, edts, mopm, lgukr |
Komen we een woord uit (1a) tegen in een tekst, dan kunnen we in ieder geval overwegen het te gaan opzoeken in een woordenboek; bij de woorden uit (1b) komt die gedachte niet bij ons op: dit soort lettercombinaties, dat fonologisch voor Nederlanders haast niet te realiseren is, kan gewoon geen Nederlands zijn. De intuïties van de taalgemeenschap hierover zijn tamelijk duidelijk en consequent; die intuïties zijn uitgebreid onderzocht, hetgeen geresulteerd heeft in de formulering van een aantal regels en generalisaties over de foneerastructuur van het Nederlands. Ons programma VUN bevat een aantal van die regels. Ingevoerde lettercombinaties worden aan deze regels getoetst en ze worden, naar gelang het resultaat van die toetsing, ondergebracht in een lijst ‘uitspreekbaar’ (ofwel ‘fonologisch welgevormd’) of ‘onuitspreekbaar’. In een aantal volgens het programma uitspreekbare woorden wordt ook nog een soort van syllabestructuur aangebrachtGa naar eind1..
Fonologie
De distributie van fonemen in Nederlandse woorden staat in de belangstelling sinds er in Nederland fonologie beoefend wordt. De eerste grondige monografie hierover is van Bakker (1971), maar voor die tijd vinden we al resultaten van systematisch onderzoek bij Cohen e.a. (1959), Moulton (1962) (alleen klinkers), Oosterlynck (1962) en Brandt Corstius (1970). Onderzoek na 1971 neemt dikwijls Bakker (1971) als
uitgangspunt: Danneels (1979), Trommelen (1983), Van der Hulst (1984). Deze onderzoekingen vallen op verschillende gronden in te delen. Eerste criterium kan zijn onderzoek naar actueel voorkomen versus onderzoek naar intuïties (welgevormdheidsoordelen). Brandt Corstius (1970) lijkt de meest fervente aanhanger van de eerste aanpak (p. 36):
‘Our aim is a quantitative determination of the structure of the Dutch [...] syllable tokens. Not the question whether something happens but how often it occurs is under discussion.’
Zijn aanpak is dan ook het met de computer analyseren van een grote hoeveelheid tekstmateriaal, hetgeen resulteert in een aantal lijsten van de frequenties van foneemcombinaties op de diverse posities in het Nederlandse woord.
Van der Hulst (1984) lijkt een van de extremere aanhangers van de andere aanpak (p. 75):
‘For the analysis of Dutch syllable structure presented here I will describe my own speech.’
Vanuit dit methodologisch uitgangspunt maakt Van der Hulst bijvoorbeeld geen onderscheid tussen stemhebbende g en stemloze ch, terwijl het woord schreeuw in zijn aanpak niet met schr maar met sr begint.
Een tweede indelingscriterium zou kunnen zijn onderzoek naar grafeemstructuur of naar foneemstructuur. Brandt Corstius (1970) kiest weer voor de eerste aanpak: hij onderzoekt de structuur van ‘Dutch spelling syllable tokens’, waar hij evenwel aan toevoegt (p. 36):
‘The phonetic or phonological syllable can, [...] to a large extent be derived from the spelling syllable.’
De ‘echte fonologen’ daarentegen gaan uit van de klank- in plaats van de letterstructuur: zo zal een grafeemonderzoeker concluderen dat b woordfinaal voorkomt (2a) waar een foneemonderzoeker alleen de stemloze
p woordfinaal aantreft (2b)Ga naar eind2..
| (2) | a. | eb, rob, kwab |
| b. | /ep/, /rop/, /kwap/ |
Niet geschikt als indelingscriterium, wel een bron van onenigheid zijn verschillen als het volgende: Bakker (1971) beschouwt het eindcluster van promptst als onuitspreekbaar; zijn algemene conclusie is, dat het Nederlandse eindcluster maximaal vier consonanten bevat (p. 83). Van der Hulst (1984) vindt datzelfde woord promptst wel uitspreekbaar, waaruit hij de conclusie trekt, dat het Nederlandse eindcluster vijf consonanten kan bevatten (p. 77). Bakker komt op grond van vormen als herfst en sprak tot de slotsom, dat de langste mogelijke Nederlandse syllabe acht segmenten bevat, en wel volgens het patroon CCCVCCCC, Van der Hulst meent dat de monosyllabe maximaal negen segmenten kan bevatten: als mogelijk woord geeft hij spromptst, met structuur CCCVCCCCC.
Alle onderzoekers wijzen op het verschil tussen gelede en ongelede woorden in dezen: vijfvoudige eindclusters, zo ze al voorkomen, treffen we alleen aan in gelede woorden, terwijl ook viervoudige eindclusters in ongelede woorden hoogst zeldzaam zijn (Trommelen (1983), p. 62-63): alleen herfst en ernst lijken op te treden.
Uitwerking
Voor ons programma hebben wij er, tamelijk willekeurig, voor gekozen, gebruik te maken van de regels die te vinden zijn in Booij (1981). In een tiental pagina's (89-98) geeft Booij een samenvatting van de meeste onderzoeksresultaten tot 1981, waarbij hij vooral veel ontleent aan Bakker (1971). Dit impliceert onder meer dat promptst bij hem, zowel als bij ons, als onuitspreekbaar geldt.
In het algemeen zijn we grafematisch te werk gegaan, dus uitgegaan van het spellingsbeeld; af en toe hebben we een ‘concessie aan de fonologische werkelijkheid’ gedaan, zoals bij qu en x, die we respectievelijk vervangen door kw en ks. Niet alle regels uit Booij zijn even gemakke-
lijk te programmeren; we kunnen een drietal gevallen onderscheiden:
1. de betreffende regel is te vaag of heeft te veel uitzonderingen;
2. de regel maakt onderscheid tussen klanken die met hetzelfde grafeem aangeduid worden, bijvoorbeeld e vs. sjwa;
3. de regel maakt onderscheid tussen bijvoorbeeld syllabe-initiële en woord-initiële clusters.
Een voorbeeld van een regel van het eerste type, vaag en met uitzonderingen, is de volgende (Booij p. 89, zie ook Trommelen (1983) p. 73):
‘Er zit een algemene tendens in de opbouw van de syllabe: [...] de sonoriteit van de klanken neemt van binnen naar buiten toe af.[...] Het algemene principe voor de bouw van de syllabe kan als volgt weergegeven worden:
| (3) | C1... Cn[+syll] Cn+1...Ck | |
| sonoriteit (Cn) > sonoriteit(Cn-1) | ||
| sonoriteit(Cn+1) > sonoriteit(Cn+2) | ||
| waarbij we de volgende sonoriteitsschaal voor consonanten aannemen: | ||
| explosieven-fricatieven-nasalen-liquidae-halfvocalen | ||
| → | ||
| sonoriteit’ | ||
Gezien evenwel het aantal taalspecifieke uitzonderingen op deze regel (zie Booij (1981) p. 90) en het gebrek aan formaliseringGa naar eind3. hebben we ervan afgezien deze regel in het programma op te nemen: de winst die-ie zou opleveren wordt (vrijwel) te niet gedaan door de noodzaak van het opsommen van alle positieve en negatieve uitzonderingen. Bovendien
maakt een mengsel van positieve en negatieve uitzonderingen het programmeren niet gemakkelijk, en het programma niet overzichtelijk.
Over het derde type lastige regels valt het volgende op te merken: intervocalische clusters in Nederlandse woorden bestaan, als de klinker ervoor lang is, uit maximaal twee (bij uitzondering drie), en als de klinker ervoor kort is, uit maximaal drie (bij uitzondering vier) consonanten (zie van der Hulst 1985). Aan de andere kant vinden we in gelede woorden af en toe combinaties van een heel zwaar eindcluster met een heel zwaar begincluster: de extreemste gevallen zijn wel angstschreeuw en herfstspreeuw. In ons programma hebben we geen onderscheid gemaakt tussen syllabe-finaal en woord-finaal, en ook niet tussen geleed en ongeleed. Omdat het cluster -ngst aan het woordeinde kan voorkomen, en omdat schr- woordinitiëel voorkomt, is ook de combinatie van die twee in angstschreeuw goed. We hadden natuurlijk wel onderscheid kunnen maken tussen woord-perifeer en -intern, maar dan zouden veel gelede woorden als onuitspreekbaar afgekeurd worden.
Het programma
We hebben het programma VUN geschreven in de tamelijk onbekende programmeertaal SNOBOL4, een taal die in de jaren zestig ontwikkeld is in de BELL-laboratories (zie Griswold e.a. (1971) en Maurer (1976)). Anders dan bekendere talen als BASIC en PASCAL is SNOBOL4 geen taal voor algemeen gebruik. SNOBOL is namelijk speciaal ontwikkeld met het doel, het werken met strings, dat zijn rijen tekens, ofte wel tekst, zo gemakkelijk mogelijk te maken. De SNOBOL-versie die we hier gebruikt hebben is die van de SPITBOL-compiler zoals die geïmplementeerd is in de AMDAHL/IBN-machine van het Leidse CRI. Een zeer belangrijke en hoogst bruikbare standaardfunctie in SNOBOL is ‘pattern matching’ (patroonherkenning: zie Griswold e.a. (1971) Ch. 2, Maurer (1976) Ch. 2 en 4): je definiëert een patroon, bij voorbeeld aangrenzend twee maal hetzelfde letterteken, en dan zoek je je tekst af op voorkomen van dit patroonGa naar eind4.. Een andere standaardfunctie die zeer bruikbaar is, maar die we in lang niet alle andere programmeertalen aantreffen, is vervanging, een faciliteit waar we dankbaar gebruik van maken bij lettertekens als
q, x en c.
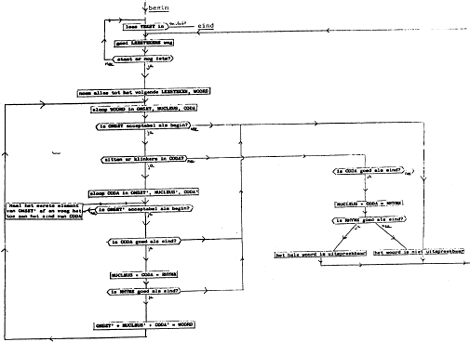
Ruwweg is de gang van zaken in het programma als volgt (zie het stroomdiagram in bijlage 1): de regel voor regel ingelezen tekst wordt gesplitst in woorden. Een paar uitheemse tekens, zoals c, worden vervangen door letters waarvan de klankwaarde wat eenduidiger is. Van ieder woord wordt nagegaan of het uitspreekbaar is, en wel op de volgende manier.
Allereerst wordt bekeken of het woord-initiële consonantcluster welgevormd (uitspreekbaar) is: enerzijds wordt dat cluster gecontroleerd op het voorkomen van in ieder geval onwelgevormde combinaties, zoals tl-en kz-, anderzijds wordt nagegaan of het cluster mogelijk gelijk is aan een goed cluster. Die ‘goede clusters’ zijn gedefiniëerd als patroon: dat kan zijn een consonant naar keuze (uitgezonderd de ng-), maar ook een s gevolgd door vrijwel iedere andere medeklinker.
Is het woordbegin goed, dan wordt gekeken naar de volgende consonantgroep: is die woordfinaal, dan wordt gekeken of hij als zodanig acceptabel is, is hij woordintern, dat wil zeggen dat er klinkers op volgen, dan wordt nagegaan of hij te analyseren valt als combinatie van een zo lang mogelijk begincluster voorafgegaan door een welgevormd eindcluster. Is het interne eindcluster goed bevonden, dan wordt gekeken naar het volgende intervocalische cluster, dat op dezelfde manier aangepakt wordt, enzovoorts, totdat het eindcluster bereikt is. Zijn alle consonantclusters uitspreekbaar, en worden ze door minstens een vocaal van elkaar gescheiden, dan komt het woord in de lijst van uitspreekbare woorden, met daarbij een suggestie voor een verdeling in lettergrepen. Het eerste niet-uitspreekbare consonantcluster, alsmede het ontbreken van klinkers, leidt tot opname in de lijst van niet-uitspreekbare woorden. Op een paar uitzonderingen na (u verplicht voor finale w, geen r na diftong, etcetera) wordt niet naar vocaalclusters gekeken: het bekende Opperlandse papagaaieeiooiuieaaier wordt dan ook opgevat als drielettergrepig.
We zagen zojuist dat we bij woordinterne clusters nagingen of ze te
analyseren waren als combinatie van een zo lang mogelijk welgevormd begincluster voorafgegaan door een welgevormd eindcluster: we hanteren dus een tamelijk rigide maximale-onsetprincipe. Booij (1981) hanteert ook zoiets (p. 81), Hamans (1985) meent dat er uitzonderingen op gemaakt moeten worden, en Van der Hulst (1984) geeft een formele definitie (p. 69):
‘Given two possible parsings, choose the one where onsets are maximalized, such that no illformed syllables arise.’
Onze aanpak is wat anders, maar het resultaat is hetzelfde: bij ieder intervocalisch consonantcluster proberen we eerst, of dat in zijn geheel als onset voor de volgende syllabe acceptabel is. Is dat niet het geval, dan verplaatsen we de meest linkse letter van die onset naar het eind van de coda van de voorafgaande syllabe. Wederom kijken we of de onset, in zijn nieuwe, verkorte vorm, acceptabel is. Is dat niet het geval, dan halen we weer het meest linkse element weg, enzovoorts. Door deze iteratieve aanpak wordt de onset steeds korter, en op een zeker moment wordt hij in elk geval als uitspreekbaar beoordeeld (op zijn laatst, als hij nog maar een letter bevat). Is de onset eenmaal goed, dan pas testen we de coda, die in de loop van het voorafgaande een flinke lengte gekregen kan hebben. Is die coda uitspreekbaar, dan geldt het gehele cluster als welgevormd, is hij onuitspreekbaar, dan wordt het hele intervocalische cluster fout gerekend, en daarmee het hele woord.
Een voorbeeld van zo'n analyse: het intervocalische cluster ngstschr van angstschreeuw:
| (4) | eerste stap | ||
| ONSET: *ngstschr | CODA: (a) | ||
| tweede stap | |||
| ONSET: *tschr | CODA: (a)n | ||
| derde stap | |||
| ONSET: *stschr | CODA: (a)ng | ||
| vierde stap | ||
| ONSET: *tschr | CODA: (a)ngs | |
| vijfde stap | ||
| ONSET: schr | CODA: (a)ngst | |
In dit geval zijn zowel ONSET als CODA welgevormd, zodat het gehele intervocalische cluster als welgevormd gelden mag. De afbreekstreep wordt (toevallig) goed geplaatst, namelijk tussen de t en de s, maar vooral in veel samenstellingen gaat dat volstrekt mis:
| (5) | ophaalbrug (o-phaal-brug) |
| antiraketraket (an-ti-ra-ke-tra-ket) | |
| ijspret (ij-spret) | |
| handarbeid (han-dar-beid) | |
| rotsig (ro-tsig) |
Veel foute afbrekingen zouden we kunnen voorkomen door het aanleggen van een morfemen- en problemenlijst maar volgens Brandt Corstius (1978, p. 111) wordt het programma nooit 100 % foutloos (Boot (1984, p.37) noemt een programma van 1300 regels dat wel foutloos zou werken; Smit (1984) werkt enige van Brandt Corstius' ideeën uit, en laat zien, dat in een niet al te groot programma een heel laag foutenpercentage bereikbaar is). Aan zo'n lexicon-achtige lijst zijn we evenwel niet begonnen, omdat ons doel niet een syllabificatieprogramma, maar een uitspreekbaarheidsoordelengenerator was. Als zodanig werkt het programma goed: een ‘foute’ syllabificatie heeft geen invloed op de juistheid van het oordeel.
De hierboven geschetste aanpak bij het splitsen van woorden in lettergrepen zou een verkeerd oordeel genereren in gevallen waarin een kort cluster, bijvoorbeeld -Xc, als coda fout is, terwijl datzelfde cluster, verlengd met een of meer consonanten, dus -Xcc of -Xc*, als coda goedgekeurd wordt. Dit hypothetische geval komt bij ons weten echter niet voor. Echter, in woorden als bastaard, rotsig en drukwerk wordt de syllabegrens gelegd voor de eerste consonant. In feite zijn de syllaben voor die consonant, waarvan het rhyme slechts bestaat uit een korte
beklemtoonbare vocaal, onwelgevormdGa naar eind5.. Maar, zoals we al signaleerden, we hebben ons in het algemeen bijzonder weinig bezig gehouden met vocalen, en bovendien, dru-kwerk is onzes inziens een mogelijk Nederlands woord, met een niet on-Nederlands syllabificatiepatroon, gezien gevallen als april en cabriolet (zie ook Van der Hulst 1985).
Automaten en grammatica's
VUN valt te beschouwen als, of in ieder geval te herschrijven tot, een accepterende stapelautomaat (pushdown automaton, zie Hopcroft and Ullman (1979) Ch. 5) ofte wel een parser of ontleder (zie Lewis and Papadimitriou (1981) p. 109). Barr and Feigenbaum (ed.) (1981) definiëren parsen als (p. 229):
‘the “delinearization” of linguistic input, that is, the use of grammatical rules and other sources of knowledge to determine the functions of the words in the input sentence (a linear string of words) in order to create a more complicated data structure, for example a DERIVATION TREE.’ (zie ook Winograd (1983) Ch. 3).
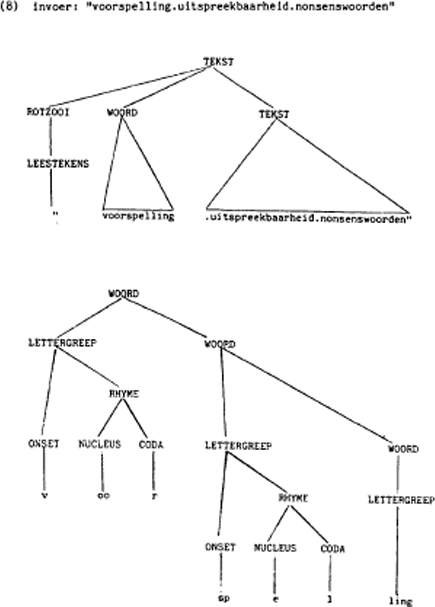
Meestal slaat ‘parse(re)n’ op ontleden op zinsniveau, maar formeel is er niets op tegen om ook de woorden zelf te ontleden: dan noemen we ieder letterteken ‘woord’ en iedere acceptabele combinatie van lettertekens ‘ zin’. Omdat het programma voor iedere niet-oneindige string binnen eindige tijd met een en slechts een oordeel ‘uitspreekbaar’ of ‘niet uitspreekbaar’ komt, geloven we te mogen zeggen dat het programma deterministisch is (zie Lewis and Papadimitriou (1981) p. 134 ev.). Zoals bekend (Brandt Corstius (1974) p. 54 ev., Ollongren en Van der Weide (1979) p.74 ev.) accepteren stapelautomaten die over precies een stapel beschikken de contextvrije talen, dus de talen die door contextvrije grammatica's gegenereerd worden. Met andere woorden, het moet mogelijk zijn, uit het programma een contextvrije herschrijfgrammatica voor Nederlands-achtige woorden te destilleren. Een stukje van die contextvrije grammatica van VUN zou men als volgt kunnen noterenGa naar eind6. (cf. Brandt Corstius (1970) 1):
| (6) | a. | TEKST | → | ROTZOOI WOORD TEKST |
| b. | ROTZOOI | → | LEESTEKEN* | |
| c. | WOORD | → | LETTERGREEP (WOORD) | |
| d. | LETTERGREEP | → | ONSET RHYNE | |
| e. | ONSET | → | CONSONANT* | |
| f. | RHYME | → | NUCLEUS CODA, VOCAAL* CONSONANT* | |
| g. | NUCLEUS | → | VOCAAL* | |
| h. | CODA | → | CONSONANT* |
(de regels (6a) en (6c) zijn recursief).
De grammatica is in deze vorm nog veel te simplistisch: immers, er zijn allerlei restricties op de regels (6e), (6g) en (6h). Een regel als (6e) ziet er dan ook feitelijk meer uit als:
| (7) | e. | ONSET | → | CONSONANT, t [h, j, r, s, w], b [r, l],... |
Voorts geldt ook nog het volgende (Brandt Corstius (1974), p. 49-50):
‘Er bestaat een natuurlijke correspondentie tussen de (indirecte) afleiding in een contextvrije grammatica en een boom. Bij iedere stap, of directe afleiding, wordt immers een hulpteken herschreven in een rijtje hulp- en eindtekens. In een boom geeft men dat aan door vanuit een knoop, met dat ene hulpteken als naam, takken te laten gaan naar elk van de hulp- en eindtekens waarin hij herschreven wordt.’
Veel van de door het programma gecreëerde boomstructuren vernietigen we
weer door concatenatie; het enige wat er in de uitvoer nog van te zien is, zijn de lettergreep-streepjes. Machine-intern worden er echter almaar bomen opgericht, ongeveer als volgt:
Mogelijke toepassingen
Wij stellen ons voor dat VUN of een VUN-achtig programma op diverse manieren praktisch toepasbaar is. Wat nu volgt is een niet uitputtende opsomming:
1. Als correctiehulpmiddel in een tekstverwerker of zetmachine (Brandt Corstius (1978) p. 139):
‘Ook wie geen Frans kent zal in een Franse tekst het woord “maintenxnt” voor een drukfout houden. Het corrigeren ervan is een moeilijker opdracht [...]. Een foutief gedrukt woord zal als het geen systematische fout betreft, de frequentie 1 hebben, maar helaas bezit de helft van de woordtypen uit een tekst die frequentie. Een beter idee is om de regels die de lettervolgorde in woorden beheersen vast te leggen en te zien welke woorden daar niet aan voldoen. Tenslotte kan men elk woord in een woordenboek opzoeken, maar dan komen de eigennamen, samengestelde woorden, en woorden uit andere talen, weer roet in het eten gooien.’
VUN is, zoals we zagen, een programma van het tweede type: in de huidige versie komen de foute woorden in een andere lijst dan de goede, maar met een kleine wijziging moet het mogelijk zijn, het programma in te bouwen in een tekstverwerker, zodanig dat foutgetikte woorden die de regels schenden gaan knipperen of op een andere manier de aandacht van de intikker (m/v) trekken. Boot (1984) spreekt bij de bespreking van een soortgelijk programma van (p.42):
‘[een] intelligente spellingscorrector [...] die in feite een expertsysteem inhoudt’.
Het voornaamste probleem van al dit soort correctieprogramma's, hun principiële onvolkomenheid, is ook eigen aan VUN: terecht wordt aandacht gevraagd voor een uitheemse naam als Bani Sadr, maar een tikfout die van in, is maakt wordt alleen opgemerkt door een programma met kennis van de syntaxis.
2. Als onderdeel van een afbreekroutine in zo'n zelfde tekstverwerker of zetmachine (zie hierboven), al dient VUN dan te worden aangevuld hetzij met de aangeduide morfemen- en problemenlijst, hetzij met een morfologische parser.
3. Ten behoeve van psychologen en farmaceuten (Brandt Corstius (1978) p. 110):
‘De analyse van de Nederlandse lettergreep kan ook nog een heel ander doel dienen: het produceren van Nederlandsachtige lettergrepen; en, door die achter elkaar te plaatsen, van Nederlandsachtige woorden. Hiervoor bestaat belangstelling zowel bij psychologen, die voor hun proeven vaak de beschikking over nonsenslettergrepen van bepaalde eigenschappen willen hebben, als bij de industrie, vooral de farmaceutische, voor het bedenken van nieuwe merknamen.’
Bij dit gebruik van VUN zouden met behulp van een toevalsgenerator willekeurige lettercombinaties gegenereerd kunnen woorden; VUN kan dan de uitspreekbare, dus de bruikbare, selecteren.
4. Als middel om de fonologische regels te toetsen en te verfijnen: aan de ene kant kun je, als je je fonologische theorie op deze manier tot een programma verwerkt, die theorie controleren met heel veel testmateriaal, bijvoorbeeld door grote hoeveelheden Nederlandse tekst (een woordenboek!) als invoer te gebruiken. In dat geval blijken diverse Nederlandse woorden, zoals twaalf, wierp, en zwierf, fonologisch onwelgevormd te zijn (zie Van der Hulst (1984) p. 100). Aan de andere kant dwingt de computer de taalkundige tot grote exactheid en nauwkeurigheid (zie Brandt Corstius (1978) p. 128).
5. Als onderdeel van een programma voor tekst-naar-spraak-conversie: met behulp van VUN (in ietwat verfijnde vorm) kunnen syllabegrenzen gegenereerd worden, die je nodig hebt voor het bepalen van de juiste uitspraak. Ook is het mogelijk om met behulp van een VUN-achtig programma (op basis van de fonologische structuur) onderscheid te maken tussen gelede en ongelede woorden, en zoals bekend gelden voor gelede woorden andere klemtoonregels dan voor ongelede (Van der Hulst (1984) passim).
Algemene opmerkingen ter afsluiting
1. Als je probeert een (stuk) taalkundige theorie om te zetten in een computerprogramma, word je voortdurend voor de keuze gesteld: wat is regel, wat is uitzondering? We kwamen dat al tegen bij het geval promptst. Wij hebben hier als vuistregel gehanteerd, dat we met een regel te maken hebben als iets vaker dan in een uniek woord voorkomt. Zo is gn- bij ons een acceptabele onset omdat deze combinatie vaker dan eenmaal voorkomt, en nog in (tamelijk) inheemse woorden bovendien (gnuiven, gniffelen). Hoogstwaarschijnlijk hebben we deze vuistregel niet al te consequent toegepast: er zijn minstens vier woorden met een intervocalisch zz-cluster (mazzel, pizza, puzzel, razzia) maar die rekenen we, tezamen met fez en jazz, toch maar in een keer fout met behulp van de regel ‘geen z in de coda’.
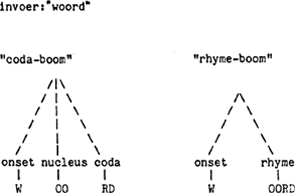
2. Na de (uitheemse) onset chl- komt alleen o(o) voor (chloor, chlorophyl)Ga naar eind7); na ts- alleen lange klinkers (tsaar, tseetseevlieg); met uitzondering van veulen komt er geen eu voor na v-, en na de combinatie Cw (consonant gevolgd door geronde halfvocaal) treden nauwelijks geronde vocalen op (Bakker (1971) p.131, Danneels (1979) p. 47, Van der Hulst (1984) p. 56 en Ch. 3): al dat soort generalisaties valt uitstekend te verwerken in een computerprogramma. Zo'n stap vormt evenwel een aanzienlijke verrijking van je theorie: daarmee wordt namelijk het standpunt verlaten, dat de lettergreep bestaat uit een onset en een rhyme, en gebruik je ook (zij het slechts af en toe) behalve de standaardboom (hieronder links) ook nog een boom die vertakt in onset en nucleus (rechts):

(cf. Bakker (1971) p. 132 en Van der Hulst (1934) part II).
Literatuur
| Van Bakel, J.
(1984) |
Automatic Semantic Representation. Dordrecht: Foris. |
| Bakker, J.J.M.
(1971) |
Constant en variabel. De fonematische structuur van de Nederlandse Woordvorm. Asten: Schiks' (Diss. UvA 1971). |
| Barr, A. & E.A. Feigenbaum
(1981) |
The Handbook of Artificial Intelligence. Vol. 1, Stanford [etc.]: Kaufman. |
| Berwick, R.C. & A.S. Weinberg
(1982) |
‘Parsing Efficiency, Computational Complexity, and the Evaluation of Grammatical Theories’, in LI 13, 165-191. |
| Booij, G.E.
(1981) |
Generatieve fonologie van het Nederlands. Utrecht: Het Spectrum (Aula Paperback 55). |
| Boot, M.N.M.
(1984) |
Taal, tekst, computer. Katwijk: Servire. |
| Brandt Corstius, H.
(1970) |
Exercises in Computational Linguistics. Amsterdam: Mathematisch Centrum (Diss. Uva 1970). |
| (1974) | Algebraīsche taalkunde. Utrecht: Oosthoek's (Academische paperbacks). |
| Chomsky, N.A.
(1981) |
Lectures on Government and Binding. Dordrecht: Foris (SGG 9). |
| - & H. Lasnik
(1977) |
‘Filters and Control’, in: LI 8, 425-504. |
| Cohen, A. [e.a.]
(1959) |
Fonologie van het Nederlands en het Fries. Den Haag: Nijhoff. |
| Danneels, M.
(1979) |
Morfeemstructuurcondities in (+native) Nederlands. (Diss. Gent 1978-79). |
| Griswold, R.E. [e.a.]
(1971) |
The SNOBOL4 Programming Language. 2e dr., Englewood Cliffs: Prentice-Hall. |
| Hamans, C.S.J.M.
(1985) |
Abstract voor een lezing, te houden op de TIN-dag 1985. Te verschijnen in LIN 1985. Dordrecht: Foris. |
| Hopcroft, J.E. & J.D. Ullman
(1979) |
Introduction to Automata Theory, Languages and Computation. Reading [etc.]: Addisson Wesley. |
| Hulst, H.G. van der
(1984) |
Syllable Structure and Stress in Dutch. Dordrecht: Foris (Diss. Leiden 1984). |
| (1985) | ‘Ambisyllabicity in Dutch’, te verschijnen in: LIN 1985. Dordrecht: Foris. |
| Lewis, L.R. & C.H. Papadimitriou
(1981) |
Elements of the Theory of Computation. Englewood Cliffs: Prentice-Hall |
| Maurer, W.D.
(1976) |
The Programmer's Introduction to SNOBOL. New York: Elsevier. |
| Moulton, W.G.
(1962) |
‘The Vowels of Dutch: Phonetic and Distributional classes’, in: Lingua 11, 294-313. |
| Ollongren, A. & Th.P. van der Weide
(1979) |
Abstracte automaten en grammatica's. Den Haag: Academie Service. |
| Oosterlynck, J.
(1964) |
‘Distributie van de fonemen in de Nederlandse éénlettergrepige monomorfematische substantieven’, in: Taal en tongval 14, 51-64. |
| Smit, P.R.
(1984) |
‘A Hyphenation Algorithm for HPWord’, in: Hewlett-Packard Journal 35, 9 (sept. '84), 26-30. |
| Trommelen, M.T.G.
(1983) |
The Syllable in Dutch, with special reference to diminutive formation. Dordrecht: Foris (diss. Utrecht 1983). |
| Weizenbaum, J.
(1984) |
Computer Power and Human Reason: from Judgement to Calculation. Harmondsworth [etc.]: Pelican. |
| Winograd, T.
(1983) |
Language as a cognitive proces. Vol. 1: Syntax. Reading [etc.]: Addisson Wesley. |
Bijlage 1
Bijlage 2
Dit is een voorbeelduitdraai van VUN. De eerste regel (‘HIEh BEGINT DE UITDRAAI’) is een produkt van het programma. Dan volgt er een stuk tekst, exact zoals het is ingevoerd, inclusief leestekens en spaties. Vervolgens volgt er een mededeling over het aantal geanalyseerde woorden (‘HET AANTAL WOORDEN IN DEZE TEKST IS 491’). Vervolgens krijgen we een lijstje met ‘foute woorden’, waarbij aangemerkt verdient te worden, dat ervoor gekozen is, klinkerloze lettercombinaties (afkortingen) en getallen als niet-uitspreekbaar te kwalificeren. Tot slot volgt een lijst met ‘goede woorden’ waarbij steeds tussen haakjes een uitspraaksuggestie gegeven wordt. Naarmate men vordert de lijst van goede woorden wordt het verhaal steeds onbegrijpelijker. Dit komt niet zozeer door het verwijderen van de leestekens (dan zou de tekst immers een constante mate van onleesbaarheid hebben) als weldoor de in het programma opgenomen strategie, van ieder ingelezen woord eerst na te gaan of het al op uitspreekbaarheid beoordeeld is. Is dat inderdaad het geval, dan wordt er, uit overwegingen van efficiëntie, niet neer naar gekeken.

- eind*
- In dit stuk wordt iets verteld over het programma VUN, dat de auteur samen met Reinder Verlinde gemaakt heeft in het kader van een cursus Computerlinguistiek. Deze cursus werd in het eerste semester van het studiejaar 1984-85 in Leiden gegeven door Prof. Dr. H.C. Brandt Corstius. Schrijver dezes is Marcel Albers, Hende Bauer, Hans Bennis, Harry van der Hulst, John van Lit, Alexander Ollongren, Reinder Verlinde en Pim Wehrmann, alsmede het publiek op de TABU-dag 1985 dank verschuldigd voor hun commentaar op eerdere versies van dit stuk.
- eind1.
- Er wordt geen syllabestructuur aangebracht in klinkerclusters: chaos bijvoorbeeld geldt bij ons als monosyllabisch.
- eind2.
- We hebben het hier natuurlijk over de uitspraak van losse woorden, niet over verbonden spraak.
- eind3.
- Voor een wat meer belovende, gekwantificeerde schaal zie Van der Hulst (1984) p. 97.
- eind4.
- Dit patroon komt uitstekend van pas on Booij's regel (11) (p. 90) in het programma te verwerken. De regel
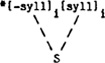
wordt vertaald in het SNOBOL-statementONSET LEN(1) $ Z *Z
(zie Maurer (1976) p. 73). Deze regel komt twee maal in ons programma voor, een keer werkend op ONSET, zoals hier, een keer op CODA. In een keer het hele woord afzoeken op dubbele elementen zou efficienter zijn, maar dat gaat mis bij dubbele consonanten rond een syllabegrens (bakker) en bij dubbel geschreven klinkers (boot).

- eind5.
- Op de regel dat rhymes niet alleen uit een beklemtoonbare vocaal kunnen bestaan zijn overigens enige uitzonderingen, die bijzonder gespeld worden: goh, bah.
- eind6.
- Misschien is de grammatica toch wel context-gevoelig, ondanks dat hij deterministisch is. Problematisch zijn met name de rhyme-restricties (geen diftong voor r enzovoorts): dat zijn immers een soort filters. In literatuur als Chomsky and Lasnik (1977) en Chomsky (1981) is niets te vinden over de invloed van filters op de algebraische eigenschappen van grammatica's (cf. Ollongren en Van der Weide p. 73), mogelijk omdat het stellen van die vraag in ieder geval binnen de theoretische linguistiek uit de mode is (T.A. Hoekstra, persoonlijke mededeling). Het is ook mogelijk, de zaak vanuit een andere optiek te beschouwen: feitelijk bevat het programma twee grammatica's, die op iedere string hun eigen boom oprichten:
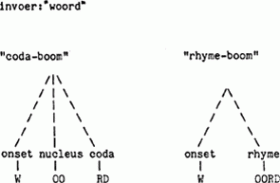
Beide bomen moeten welgevormd zijn, wil de string geaccepteerd worden. Zelfs als de beide grammatica's contextvrij zijn, dan nog hoeft hun doorsnede niet contextvrij te zijn (Lewis and Papdimitriou (1981) p. 126:THEOREM 3.5.5. The context-free languages are not closed under intersection or complementation.’)
Aan de andere kant zijn talen die door een deterministische stapelautomaat geaccepteerd worden nooit rijker dan contextvrij, maar wellicht is VUN wel helemaal niet equivalent aan een stapelautomaat. Mogelijk kunnen we niet veel meer beweren dan dat VUN, net als ieder computerprogramma dat ooit wel eens stopt, een deterministische Turing-machine is (cf. Weizenbaum (1984) passim) maar dat is nauwelijks een interessante claim.
Overigens, de regels (6d) en (6f) van de grammatica, zoals die hier genoteerd staan, zijn een nogal grove simplificatie van de de gang van zaken in het programma. Beter ware het, te noteren:hetgeen mogelijk wel in contextvrije vorm te herschrijven is, maar in deze notatie bijzonder contextgevoelig oogt. Cf. Brandt Corstius (1970) p. 50. Vergelijk evenwel de uitspraak van Van Bakel (1984) p. 2:(6d') LETTERGREEP → ONSET NUCLEUS CODA (6f') NUCLEUS CODA → RHYME ‘the possibility to generate a natural language with a contextfree grammar is of complete theoretical irrelevance.’
Berwick en Weinberg (1982, passim) zijn ook de mening toegedaan dat het niet relevant is of de grammatica contextvrij is, maar dat het belangrijk lijkt te zijn, dat de taal Efficiënt Parseerbaar is, zoals zij dat noemen: mensen begrijpen in korte tijd de zinnen die tot hen komen, dus als dat begrijpen algoritmisch gaat, dan moet het met een efficiënte algoritme gebeuren. Van de talen uit de Chomsky-hiërarchie is voor alle contextvrije, en voor een aantal contextgevoelige talen bewezen dat er efficiënte parseer-algoritmen voor bestaan.
- eind7)
- Volgens een informant bestaat er ook nog zoiets als chlamina, een medisch woord dat niet in de standaardwoordenboeken voorkomt.